
”爬虫“ 的搜索结果

结论: 在本篇博客中,我们介绍了五个实用的Python爬虫案例,并提供了相应的代码示例和解析。这些案例涵盖了不同的应用场景,包括爬取天气数据、图片下载、电影评论、新闻文章爬取和文本分析,以及股票数据爬取和...
Python是一种非常适合用于编写网络爬虫的编程语言。以下是一些Python爬虫的基本步骤:

爬虫 001 robots.txt 协议 002 了解爬虫 003 常用的re模块的正则匹配的表达式 004 reuqests请求 005 请求和响应 006 Beautifulsoup 007 牛逼的requests-html 008 request-html-render 009 解析语法 010 xpath解析 ...
模板爬虫的主要优势在于简化了爬虫的开发过程!降低了技术门槛,提高了爬虫的可维护性和灵活性

这几天在爬网站时发现有个别网站抓取时返回值为None、[ ]甚至是字段中返回“系统错误”等字眼),反复确认代码无误,怀疑是网站有反爬虫机制,尝试增加header后依然无法提取,考虑到只是提取本页面数据,并没有频繁...
这里写自定义目录标题欢迎使用Markdown编辑器新的改变功能快捷键合理的创建标题,有助于目录的生成如何改变文本的样式插入链接与图片如何插入一段漂亮的代码片生成一个适合你的列表创建一个表格设定内容居中、居左、...
多年爬虫领域老工程师深度总结反爬虫技术原理与场景,带你快速了解并掌握反爬虫技术栈知识

所以,你知道爬虫的作用了吗?
搜索引擎爬虫(优质引流???) 最近发现服务器日志上多了一些奇怪的日志 {"remote_addr":"203.208.60.66","remote_user":"","time_local":"25/Oct/2021:14:34:27 +0800","request":"POST /api/v9494/service-...

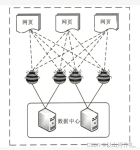
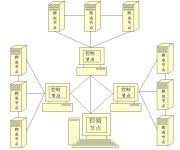
[爬虫]3.2.2 分布式爬虫的架构
标签: 爬虫
在分布式爬虫系统中,通常包括以下几个主要的组成部分:调度器、爬取节点、存储节点。我们接下来将详细介绍每一个部分的功能和设计方法。
㈠爬虫简述 爬虫,又叫网络爬虫,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外还有一些名字,例如蚂蚁、自动索引、模拟程序或蠕虫。 ㈡爬虫优点 定向数据采集,数据定制化很强,数据针对性强...
综上所述,学习爬虫需要掌握一定的编程技巧和网络知识,同时需要注意实践过程中的法律法规、数据质量和反爬机制等问题。通过不断地实践和学习,我们可以提高自己的爬虫技能,并能够有效地获取和处理大量数据,为我们...

选择一个主题,用Python语言编写一个网络爬虫程序,将文字和图像等信息抓取到MySQL中保存,(如果有图片数据,图片数据可以只在数据库存放路径,图片资源存储到文件夹)。
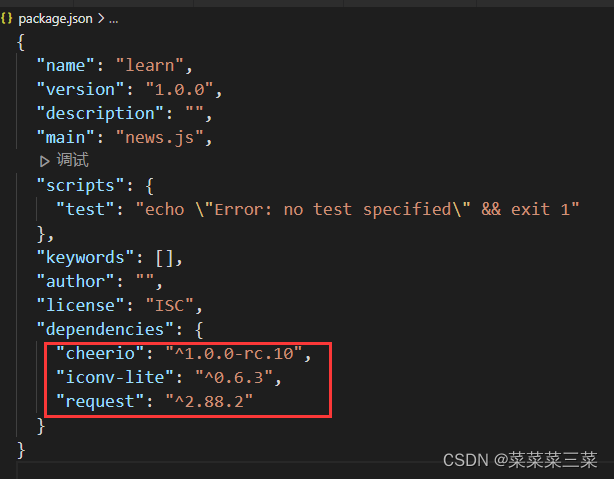
urllib 基本使用 点击 请求对象定制 点击 请求方法 get请求 点击 post请求 点击
通用搜索引擎利用爬虫程序对网站进行检索,如谷歌、百度等面向所有用户的大型搜索引擎,把种子页面作为搜索起点,力图遍历整个网络,尽可能全面搜索到人们 所需的信息。然而,针对某一特定主题,通用搜索引擎存在...
推荐文章
- confluence搭建部署_ata confluence-程序员宅基地
- SpringCloud与SpringBoot版本对应关系_springboot 2.1.1 对于的cloud-程序员宅基地
- 如何恢复硬盘数据?简单解决问题_磁盘恢复 csdn-程序员宅基地
- 苹果手机测试网络速度的软件,App Store 上的“网速测试大师-测网速首选”-程序员宅基地
- 教了一年少儿编程,说说感想和体验-程序员宅基地
- 22东华大学计算机专硕854考研上岸实录-程序员宅基地
- 如何用《玉树芝兰》入门数据科学?-程序员宅基地
- macOS使用brew包管理器_brew清理缓存-程序员宅基地
- 【echarts没有刷新】用按钮切换echarts图表的时候,该消失的图表还在,加个key属性就解决了_echarts 怎么加key值-程序员宅基地
- 常用机器学习的模型和算法_常见机器学习模型算法整理和对应超参数表格整理-程序员宅基地