【第13篇】CenterNet2论文解析,COCO成绩最高56(1),字节跳动nlp算法工程师面试-程序员宅基地
技术标签: 2024年程序员学习 算法 面试 自然语言处理
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Python全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Python知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024c (备注Python)

正文
在 COCO (Lin et al., 2014)、LVIS (Gupta et al., 2019) 和 Objects365 (Shao et al., 2019) 上的实验表明,我们的概率两阶段框架将强大的 CascadeRCNN 模型的准确性提高了 1 -3 mAP,同时也提高了它的速度。 使用标准 ResNeXt-101-DCN 主干和 CenterNet (Zhou et al., 2019a) 第一阶段,我们的检测器在 COCO testdev 上达到了 50.2 mAP。 凭借强大的 Res2Net-101-DCN-BiFPN (Gao et al., 2019a; Tan et al., 2020b) 主干和自训练 (Zoph et al., 2020),它在单尺度测试中达到了 56.4 mAP,表现优于 所有已发表的结果。 使用小型 DLABiFPN 主干和较低的输入分辨率,我们在 Titan Xp 上以 33 fps 的速度在 COCO 上实现了 49.2 mAP,在相同硬件上的性能优于流行的 YOLOv4 模型(在 33 fps 时为 43.5 mAP)。 代码和模型发布在 https://github.com/xingyizhou/CenterNet2。
=================================================================
一级检测器联合预测整个图像中密集的对象的输出类别和位置。 RetinaNet (Lin et al., 2017b) 对一组预定义的滑动锚框进行分类,并通过重新加权每个输出的损失来处理前景-背景不平衡。 FCOS (Tian et al., 2019) 和 CenterNet (Zhou et al., 2019a) 消除了每像素多个锚点的需要,并按位置对前景/背景进行分类。 ATSS (Zhang et al., 2020b) 和 PAA (Kim & Lee, 2020) 通过改变前景和背景的定义进一步改进了 FCOS。 GFL (Li et al., 2020b) 和 Autoassign (Zhu et al., 2020a) 将硬前景-背景分配更改为加权软分配。 AlignDet (Chen et al., 2019c) 在输出之前使用可变形卷积层来收集更丰富的特征用于分类和回归。 RepPoint (Yang et al., 2019) 和 DenseRepPoint (Yang et al., 2020) 将边界框编码为一组点的轮廓,并使用该点集的特征进行分类。 BorderDet (Qiu et al., 2020) 沿边界框汇集特征以更好地定位。大多数一级检测器都有合理的概率解释。
虽然一级探测器已经取得了有竞争力的性能(Zhang et al., 2020b; Kim & Lee, 2020; Zhang et al., 2019; Li et al., 2020b; Zhu et al., 2020a),但它们通常依赖于更重的探测器 将分类和回归分支分开而不是两阶段模型。 事实上,如果词汇量(即对象类集)很大(如在 LVIS 或 Objects365 数据集中),它们不再比它们的两阶段对应物快。 此外,一级检测器仅使用正细胞的局部特征进行回归和分类,有时会与对象错位(Chen 等,2019c;Song 等,2020)。
我们的概率两阶段框架保留了单阶段检测器的概率解释,但分解了多个阶段的概率分布,从而提高了准确性和速度。
两级探测器 首先使用区域提议网络 (RPN) 生成粗略的对象提议,然后使用专用的 per-region head 对它们进行分类和细化。 FasterRCNN(Ren 等人,2015 年;He 等人,2017 年)使用两个完全连接的层作为 RoI 头。 CascadeRCNN (Cai & Vasconcelos, 2018) 使用 FasterRCNN 的三个级联阶段,每个阶段都有不同的正阈值,以便后面的阶段更加关注定位精度。 HTC (Chen et al., 2019a) 利用额外的实例和语义分割注释来增强 CascadeRCNN 的阶段间特征流。 TSD (Song et al., 2020) 将每个 RoI 的分类和定位分支解耦。
在许多情况下,两级检测器仍然更准确(Gupta 等人,2019 年;Sun 等人,2020 年;Kuznetsova 等人,2018 年)。 目前,所有两阶段检测器都使用相对较弱的 RPN,最大限度地提高前 1K 个提案的召回率,并且在测试时不使用提案分数。 大量的提议减慢了系统的速度,基于召回的提议网络不直接提供与一级检测器相同的清晰概率解释。 我们的框架解决了这个问题,并将强大的与类别无关的单阶段目标检测器与后期的分类阶段相结合。 我们的第一阶段使用更少但质量更高的区域,从而产生更快的推理和更高的准确性。
其他探测器。 一系列物体检测器通过图像中的点识别物体。 CornerNet (Law & Deng, 2018) 检测左上角和右下角,并使用嵌入特征对它们进行分组。 ExtremeNet (Zhou et al., 2019b) 检测四个极值点 并使用额外的中心点将它们分组。 段等人。 (2019) 检测中心点并用它来改进角点分组。 Corner Proposal Net (Duan et al., 2020) 使用成对的角分组作为区域提议。 CenterNet (Zhou et al., 2019a) 检测中心点并从中回归边界框参数。
DETR (Carion et al., 2020) 和 Deformable DETR (Zhu et al., 2020c) 移除了检测器中的密集输出,而是使用直接预测一组边界框的 Transformer (Vaswani et al., 2017)。
基于点的检测器、DETR 和传统检测器之间的主要区别在于网络架构。 基于点的检测器使用全卷积网络(Newell 等人,2016 年;Yu 等人,2018 年),通常具有对称的下采样和上采样层,并以小步幅(即步幅 4)生成单个特征图 . DETR 式检测器(Carion 等人,2020 年;Zhu 等人,2020c)使用变压器作为解码器。 传统的一级和二级检测器通常使用由轻量级上采样层增强的图像分类网络,并产生多尺度特征 (FPN) (Lin et al., 2017a)。
=================================================================
对象检测器旨在为预定义的一组类 C 中的任何对象 i i i 预测位置 b i ∈ R 4 b_{i} \in \mathbb{R}^{4} bi∈R4 和特定于类的似然分数 s i ∈ R ∣ C ∣ s_{i} \in \mathbb{R}^{|C|} si∈R∣C∣。对象位置 b i b_{i} bi 通常由轴对齐的边界框的两个角来描述 (Ren 等人,2015;Carion 等人,2020)或通过等效的中心+大小表示(Tian 等人,2019;Zhou 等人,2019a;Zhu 等人,2020c)。 对象检测器之间的主要区别在于它们对类似然的表示,反映在它们的体系结构中。
**一级检测器(Redmon & Farhadi,2018;Lin 等,2017b;Tian 等,2019;Zhou 等,2019a)**在单个网络中联合预测对象位置和似然分数。让 L i , c = 1 L_{i,c}=1 Li,c=1 表示对对象候选 i 和类别 c 的阳性检测,让 L i , c = 0 L_{i,c}=0 Li,c=0 表示背景。大多数单阶段检测器(Lin et al ., 2017b; Tian et al., 2019;Zhou et al., 2019a) 然后使用每类独立的 sigmoid 将类似然参数化为伯努利分布: s i ( c ) = P ( L i , c = 1 ) = σ ( w c ⊤ f ⃗ i ) s_{i}=P\left(L_{i, c}=1\right)=\sigma\left(w_{c}^{\top} \vec{f}_{i}\right) si=P(Li,c=1)=σ(wc⊤f i),其中 f i ∈ R C f_{i} \in \mathbb{R}^{C} fi∈RC 是主干产生的特征,wc 是特定于类的权重向量。在训练期间,这种概率解释允许单阶段检测器简单地最大化真实注释的对数似然 l o g ( P ( L i , c ) ) log(P(L_{i,c})) log(P(Li,c)) 或焦点损失 (Lin et al., 2017b)。一级检测器在正 L ^ i , c = 1 \hat{L}_{i, c}=1 L^i,c=1 和负 L ^ i , c = 0 \hat{L}_{i, c}=0 L^i,c=0 样本的定义上彼此不同。有些使用锚点重叠(Lin 等人,2017b;Zhang 等人,2020b;Kim & Lee,2020),其他人使用位置(Tian 等人,2019)。然而,所有优化对数似然并使用类概率对框进行评分。所有直接回归到边界框坐标。
两级检测器(Ren 等人,2015 年;Cai & Vasconcelos, 2018) 首先使用对象性度量 P ( O i ) P(O_{i}) P(Oi) 提取潜在的对象位置,称为对象提议。然后,他们为每个潜在对象提取特征,将它们分类为 C \mathcal{C} C 类或具有 C i ∈ C ∪ { b g } C_{i} \in \mathcal{C} \cup\{b g\} Ci∈C∪{bg}的背景 P ( C i ∣ O i = 1 ) P\left(C_{i} \mid O_{i}=1\right) P(Ci∣Oi=1),并细化对象位置。每个阶段都是独立监督的。在第一阶段,区域提议网络 (RPN) 学习将带注释的对象 b i b_{i} bi分类为前景,将其他框分类为背景。这通常通过使用对数似然目标训练的二元分类器来完成。然而,RPN 非常保守地定义了背景区域。任何与注释对象重叠 30% 或更多的预测都可以被视为前景。这个标签定义有利于召回而不是精确和准确的似然估计。许多部分对象获得了很大的建议分数。在第二阶段,softmax 分类器学习将每个建议分类为前景类或背景之一。分类器使用对数似然目标,前景标签由带注释的对象组成,背景标签来自高分的第一阶段建议,附近没有带注释的对象。在训练期间,这种分类分布隐含地以第一阶段的阳性检测为条件,因为它只对它们进行训练和评估。第一阶段和第二阶段都有概率解释,在正负定义下分别估计对象或类的对数似然。但是,整个检测器没有。它结合了多种启发式和采样策略来独立训练第一和第二阶段(Cai & Vasconcelos, 2018; Ren et al., 2015)。最终输出仅包含第二阶段的分类分数 s i ( c ) = P ( C i ∣ O i = 1 ) s_{i}=P\left(C_{i} \mid O_{i}=1\right) si=P(Ci∣Oi=1)的框。
接下来,我们开发了两阶段检测器的简单概率解释,将两个阶段视为单个类似然估计的一部分。 我们展示了这如何影响第一阶段的设计,以及如何有效地训练两个阶段。
=======================================================================
对于每张图像,我们的目标是生成一组 K 个检测作为边界框 b 1 , … , b K b_{1}, \ldots, b_{K} b1,…,bK 具有相关的类分布 s k ( c ) = P ( C k = c ) s_{k}=P\left(C_{k}=c\right) sk=P(Ck=c) 用于类 c ∈ C ∪ { b g } c \in \mathcal{C} \cup\{b g\} c∈C∪{bg}或每个对象 k 的背景。 在这项工作中,我们保持边界框回归不变,只关注类分布。 两阶段检测器将此分布分解为两部分:与类别无关的对象似然 P ( O k ) P(O_{k}) P(Ok)(第一阶段)和条件分类 P ( C k ∣ O k ) P(C_{k}|O_{k}) P(Ck∣Ok)(第二阶段)。 这里 O k = 1 O_{k}=1 Ok=1 表示第一阶段的阳性检测,而 O k = 0 O_{k}=0 Ok=0对应于背景。 任何负面的第一阶段检测 O k = 0 O_{k}=0 Ok=0 都会导致背景 C k = b g C_{k}=bg Ck=bg 分类: P ( C k = b g ∣ O k = 0 ) = 1 P(C_{k}=bg|O_{k}=0)=1 P(Ck=bg∣Ok=0)=1。在多阶段检测器中 (Cai & Vasconcelos, 2018),分类由集成完成 多个级联级,而两级检测器使用单个分类器(Ren 等人,2015 年)。 两阶段模型的联合类分布为 :
P ( C k ) = ∑ o P ( C k ∣ O k = o ) P ( O k = o ) P\left(C_{k}\right)=\sum_{o} P\left(C_{k} \mid O_{k}=o\right) P\left(O_{k}=o\right) P(Ck)=o∑P(Ck∣Ok=o)P(Ok=o)
训练目标。 我们使用最大似然估计训练我们的检测器。 对于带注释的对象,我们最大化
log P ( C k ) = log P ( C k ∣ O k = 1 ) + log P ( O k = 1 ) \log P\left(C_{k}\right)=\log P\left(C_{k} \mid O_{k}=1\right)+\log P\left(O_{k}=1\right) logP(Ck)=logP(Ck∣Ok=1)+logP(Ok=1)
减少第一和第二阶段的独立最大似然目标。
对于背景类,最大似然目标不分解:
log P ( b g ) = log ( P ( b g ∣ O k = 1 ) P ( O k = 1 ) + P ( O k = 0 ) ) \log P(b g)=\log \left(P\left(b g \mid O_{k}=1\right) P\left(O_{k}=1\right)+P\left(O_{k}=0\right)\right) logP(bg)=log(P(bg∣Ok=1)P(Ok=1)+P(Ok=0))
该目标将第一阶段和第二阶段的概率估计与损失和梯度计算联系起来。 准确的评估需要对所有第一阶段输出的第二阶段进行密集评估,这会大大减慢训练速度。 相反,我们推导出了目标的两个下限,我们共同优化了它们。 第一个下限使用 Jensen 不等式 l o g ( a x 1 + ( 1 − a ) x 2 ) ≥ a l o g ( x 1 ) + ( 1 − a ) l o g ( x 2 ) log(ax_{1}+(1-a)x_{2})\geq alog(x_{1})+(1-a)log(x_{2}) log(ax1+(1−a)x2)≥alog(x1)+(1−a)log(x2)其中 a = P ( O k = 1 ) , a=P(O_{k}=1), a=P(Ok=1), x 1 = P ( b g ∣ O k = 1 ) x_{1}=P(bg|O_{k}=1) x1=P(bg∣Ok=1),并且 x 2 = 1 x_{2}=1 x2=1:
log P ( b g ) ≥ P ( O k = 1 ) log ( P ( b g ∣ O k = 1 ) ) \log P(b g) \geq P\left(O_{k}=1\right) \log \left(P\left(b g \mid O_{k}=1\right)\right) logP(bg)≥P(Ok=1)log(P(bg∣Ok=1))
对于第一阶段的任何高分对象,该下限最大化第二阶段背景的对数似然。 对于 P ( O k = 1 ) → 0 P\left(O_{k}=1\right) \rightarrow 0 P(Ok=1)→0或者 P ( b g ∣ O k = 1 ) → 1 P\left(bg|O_{k}=1\right) \rightarrow 1 P(bg∣Ok=1)→1来说很严格,但可以任意松 P ( O k = 1 ) > 0 P\left(O_{k}=1\right) > 0 P(Ok=1)>0 和 P ( b g ∣ O k = 1 ) → 0 P\left(bg|O_{k}=1\right) \rightarrow 0 P(bg∣Ok=1)→0. 我们的第二个界限只涉及第一阶段的目标:
log P ( b g ) ≥ log ( P ( O k = 0 ) ) \log P(b g) \geq \log \left(P\left(O_{k}=0\right)\right) logP(bg)≥log(P(Ok=0))
它使用 具有log单调性的 P ( b g ∣ O k = 1 ) P ( O k = 1 ) ≥ 0 P\left(b g \mid O_{k}=1\right) P\left(O_{k}=1\right) \geq 0 P(bg∣Ok=1)P(Ok=1)≥0 。 这个界限对于 $P\left(b g \mid O_{k}=1\right) \rightarrow 0 $ 来说很严格. 理想情况下,通过使用等式(3)和等式(4)的最大值获得最紧密的界限。 如补充材料所示,该下限在实际目标的≤ log 2 以内。 然而,在实践中,我们发现联合优化两个边界可以更好地工作。
使用下界方程(4)和正目标方程(2),第一阶段训练减少到最大似然估计,在注释对象上带有正标签,所有其他位置带有负标签。 它相当于训练一个二元单级检测器,或者一个带有严格负定义的 RPN,它鼓励似然估计而不是召回。
探测器设计。 我们的公式和标准的两阶段检测器之间的主要区别在于在检测分数方程(1)中使用了与类别无关的检测 P ( O k ) P(O_{k}) P(Ok)。 在我们的概率形式中,分类分数乘以与类别无关的检测分数。 这需要一个强大的第一阶段检测器,它不仅可以最大化提案召回率(Ren 等人,2015 年;Uijlings 等人,2013 年),而且还可以预测每个提案的可靠对象可能性。 在我们的实验中,我们使用强大的单级检测器来估计这种对数似然,如 下一节。
=========================================================================
概率两级检测器的核心组件是强大的第一级。 第一阶段需要预测准确的对象可能性,以告知整体检测分数,而不是最大化对象覆盖范围。 我们基于流行的单级检测器对四种不同的第一级设计进行了实验。 对于每个,我们强调了将它们从单级检测器转换为概率两级检测器中的第一级所需的设计选择。
RetinaNet(Lin 等人,2017b) 与传统两级检测器的 RPN 非常相似,但具有三个关键区别:更重的头部设计(RPN 中的 4 层与 1 层)、更严格的正负锚定定义以及焦点损失。 这些组件中的每一个都增加了 RetinaNet 产生校准的单阶段检测可能性的能力。 我们在第一阶段的设计中使用了所有这些。 RetinaNet 默认使用两个独立的 head 来进行边界框回归和分类。 在我们的第一阶段设计中,我们发现为两个任务使用一个共享头就足够了,因为对象或非对象分类更容易并且需要更少的网络容量。 这加快了推理 。
CenterNet (Zhou et al., 2019a) 将对象作为位于其中心的关键点,然后回归到框参数。原始的 CenterNet 在单一尺度上运行,而传统的两级检测器使用特征金字塔 (FPN)(Lin 等人,2017a)。我们使用 FPN 将 CenterNet 升级到多个尺度。具体来说,我们使用 RetinaNetstyle ResNet-FPN 作为主干(Lin 等人,2017b),输出特征图从 8 到 128(即 P3-P7)。我们将 4 层分类分支和回归分支 (Tian et al., 2019) 应用于所有 FPN 级别,以生成检测热图和边界框回归图。在训练期间,我们在固定的分配范围内根据对象大小将地面实况中心注释分配给特定的 FPN 级别(Tian 等人,2019)。受 GFL (Li et al., 2020b) 的启发,我们在中心的 3 × 3 邻域中添加了已经产生高质量边界框(即回归损失 < 0:2)的位置作为正例。我们使用到边界的距离作为边界框表示(Tian 等人,2019),并使用 gIoU 损失进行边界框回归(Rezatofighi 等人,2019 年)。我们评估了该架构的单阶段和概率两阶段版本。我们将改进后的 CenterNet 称为 CenterNet*。
ATSS (Zhang et al., 2020b) 使用每个对象的自适应 IoU 阈值对单级检测器的类似然进行建模,并使用中心度 (Tian et al., 2019) 来校准分数。 在概率两阶段基线中,我们按原样使用 ATSS(Zhang 等人,2020b),并将每个提议的中心度和前景分类分数相乘。 我们再次合并分类头和回归头以获得轻微的加速。
GFL (Li et al., 2020b) 使用回归质量来指导对象似然训练。 在概率两阶段基线中,我们删除了基于集成的回归,仅使用基于距离的回归(Tian 等人,2019)来保持一致性,并再次合并两个头部。
上述单阶段架构推断 P(Ok)。 对于每个,我们将它们与推断 P ( C k ∣ O k ) P(C_{k}|O_{k}) P(Ck∣Ok) 的第二阶段结合起来。 我们试验了两个基本的第二阶段设计:FasterRCNN(Ren 等人,2015 年)和 CascadeRCNN(Cai 和 Vasconcelos,2018 年)。
超参数。两阶段检测器 (Ren et al., 2015) 通常使用 FPN 级别 P2-P6(步长 4 到步长 64),而大多数单阶段检测器使用 FPN 级别 P3-P7(步长 8 到步长 128)。为了使其兼容,我们对一级和二级探测器使用 P3-P7 级。此修改略微改进了基线。遵循 Wang 等人(2019),我们将第二阶段的正 IoU 阈值从 0.5 增加到 0.6(对于 CascadeRCNN 为 0.6;0.7;对于 CascadeRCNN),以补偿第二阶段的 IoU 分布变化。我们在第二阶段最多使用 256 个提议框用于概率两级检测器,除非另有说明,否则基于 RPN 的模型使用默认的 1K 框。我们还将概率检测器的 NMS 阈值从 0.5 增加到 0.7,因为我们使用的提议较少。这些超参数变化对于概率检测器是必要的,但我们发现它们在我们的实验中并没有改进基于 RPN 的检测器。
我们基于detectron2 (Wu et al., 2019) 实现了我们的方法。我们的默认模型遵循检测器 2 中的标准设置(Wu 等人,2019)。具体来说,我们使用 SGD 优化器训练网络进行 90K 次迭代(1xschedule)。两级检测器的基本学习率为 0.02,一级检测器的基本学习率为 0.01,并在迭代 60K 和 80K 时下降 10 倍。我们使用多尺度训练,短边在 [640,800] 范围内,长边高达 1333。在训练期间,我们将第一阶段的损失权重设置为 0.5,因为一级检测器通常使用学习率进行训练0.01。在测试过程中,我们使用固定短边 800 和长边 1333。
我们在四个不同的主干上实例化了我们的概率两阶段框架。我们使用默认的 ResNet-50 (He et al., 2016) 模型进行设计选择之间的大多数消融和比较,然后与使用相同大型 ResNeXt-32x8d-101-DCN (Xie et al., 2017) 主干,并使用轻量级 DLA (Yu et al., 2018) 主干作为实时模型。我们还整合了最新进展(Zoph 等人,2020;Tan 等人,2020b;Gao 等人,2019a)并为高精度机制设计了一个超大型主干。关于每个主干的更多细节在补充中。
===============================================================
我们在三个大型检测数据集上评估我们的框架:COCO (Lin et al., 2014)、LVIS (Gupta et al., 2019) 和 Objects365 (Gao et al., 2019b)。 每个数据集的详细信息可以在补充中找到。 我们使用 COCO 进行消融研究并与最先进的技术进行比较。 我们使用 LVIS 和 Objects365 来测试我们框架的通用性,特别是在大词汇量的情况下。 在所有数据集中,我们报告标准 mAP。 运行时报告在带有 PyTorch 1.4.0 和 CUDA 10.1 的 Titan Xp GPU 上。
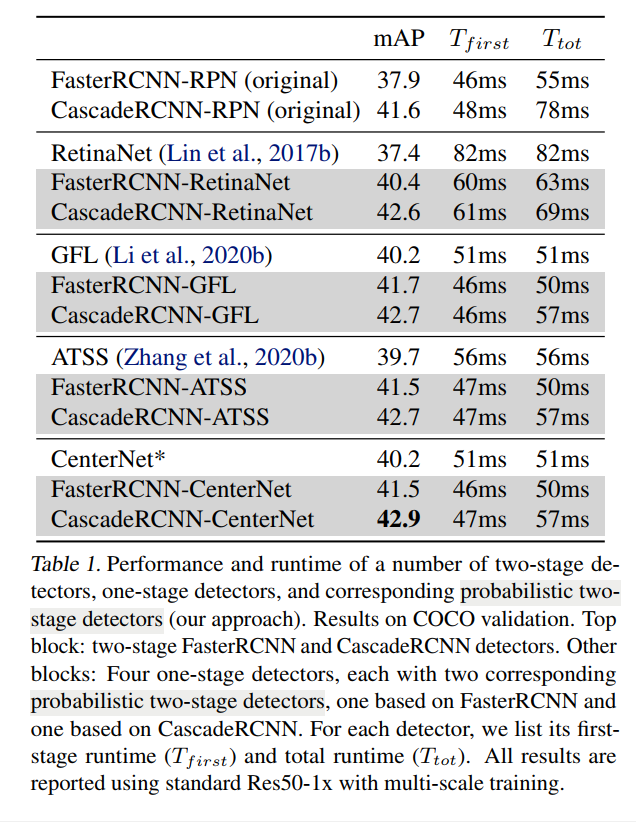
表 1 将一级和二级检测器与通过我们的框架设计的相应概率二级检测器进行了比较。 表的第一块显示了原始参考两级检测器 FasterRCNN 和 CascadeRCNN 的性能。 以下块显示了四个单级检测器(在第 5 节中讨论)和相应的概率两级检测器的性能,当使用相应的单级检测器作为概率两级框架中的第一级时获得。 对于每个一级检测器,我们展示了两种版本的概率二级模型,一种基于 FasterRCNN,一种基于 CascadeRCNN。
所有概率两级检测器的性能都优于它们的单级和两级前体。 每个概率两阶段 FasterRCNN 模型在 mAP 中比其单阶段前体提高了 1 到 2 个百分点,并且在 mAP 中比原始的两阶段 FasterRCNN 高出 3 个百分点。 更有趣的是,由于头部设计更精简,每个两阶段概率 FasterRCNN 都比其单阶段前体更快。 由于更有效的 FPN 级别(P3-P7 与 P2-P6)以及概率检测器使用更少的提议(256 与 1K),许多概率两阶段 FasterRCNN 模型比原始两阶段 FasterRCNN 模型更快。 我们观察到与 CascadeRCNN 模型类似的趋势。
CascadeRCNN-CenterNet 设计在这些概率两阶段模型中表现最好。 因此,我们在接下来的实验中采用这种基本结构,为简洁起见,将其称为 CenterNet2。
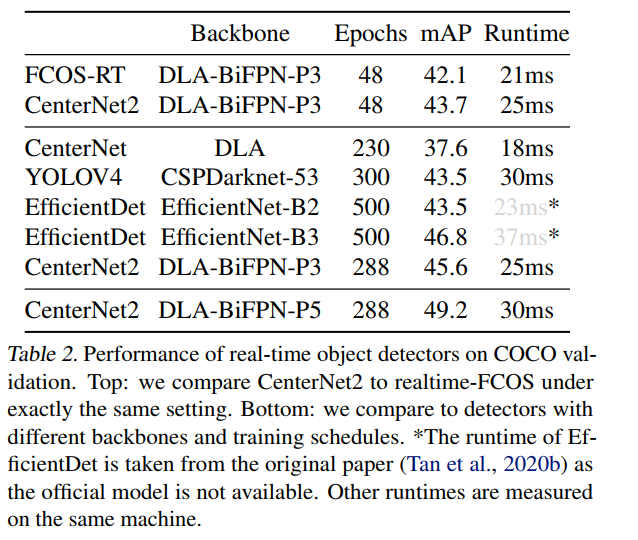
实时模型。 表 2 将我们的实时模型与其他实时检测器进行了比较。 CenterNet2 在具有相同主干和训练计划的情况下以 1:6 mAP 优于 realtime-FCOS (Tian et al., 2020),并且仅慢了 4 毫秒。 使用相同的基于 FCOS 的主干和更长的训练计划(Tan 等人,2020b;Bochkovskiy 等人,2020 年),它比原始的 CenterNet(Zhou 等人,2019a)提高了 7.7 的 mAP,并且轻松胜过 流行的 YOLOv4(Bochkovskiy 等人,2020)和 EfficientDetB2(Tan 等人,2020b)检测器在 40 fps 下具有 45.6 mAP。使用略有不同的 FPN 结构并结合自我训练(Zoph 等人,2020 年) ),CenterNet2 以 33 fps 获得 49.2 mAP。 虽然大多数现有的实时检测器都是单级的,但在这里我们展示了两级检测器可以与单级设计一样快,同时提供更高的精度。

感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的:
① 2000多本Python电子书(主流和经典的书籍应该都有了)
② Python标准库资料(最全中文版)
③ 项目源码(四五十个有趣且经典的练手项目及源码)
④ Python基础入门、爬虫、web开发、大数据分析方面的视频(适合小白学习)
⑤ Python学习路线图(告别不入流的学习)
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024c (备注python)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
需要这份系统化的资料的朋友,可以添加V获取:vip1024c (备注python)
[外链图片转存中…(img-lUvsq9I4-1713437392689)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
智能推荐
测牛学堂:软件测试之数据库操作语句sql的外键查询_sql查询外键id的数据-程序员宅基地
文章浏览阅读775次。我们之前学习的都是针对一个表的操作。如果要进行多个表之间的操作,就要用到外键把他们关联起来。外键的作用:能够让多个表进行关联,使表与表之间有联系,实现共性抽取。如果数据项比较多的情况下,把所有数据都存放在一个表中,如果表太大,影响操作效率。解决办法就是把一个表拆分成多个表,并且用外键去关联。例子:如果要设计一个员工表1)员工表:编号、姓名、年龄、性别、所在分公司、所在部门2)部门表:编号、部门名称、部门经理、主要任务3)公司表:编号、分公司名,地址、电话、法人把公司和部门的数据抽取出来,形成_sql查询外键id的数据
OpenGL学习笔记【4】——创建窗口,给窗口添加渲染颜色_opengl窗口颜色-程序员宅基地
文章浏览阅读803次,点赞14次,收藏14次。章节一讲述了OpenGL在渲染的时候需要一个Context来记录了OpenGL渲染需要的所有信息和状态,可以把上下文理解成一个大的结构体,它里面记录了当前绘制使用的颜色、是否有光照计算以及开启的光源等。不同的操作系统,都有各自的上下文创建方法,最简单的上下文可以通过创建。章节二讲述了一个一个轻量级的图形界面框架,GLFW 的是提供了处理手柄、键盘、鼠标输入章节二还创建了一个空项目章节三讲述了GLAD库是用来管理OpenGL的函数指针的,所以在调用任何OpenGL的函数之前我们需要,从而让我们。_opengl窗口颜色
java ssm 运行步骤_SSM三大框架的运行流程、原理、核心技术详解-程序员宅基地
文章浏览阅读644次。一、Spring部分1、Spring的运行流程·第一步:加载配置文件ApplicationContext ac = new ClassPathXmlApplicationContext("beans.xml");,ApplicationContext接口,它由BeanFactory接口派生而来,因而提供了BeanFactory所有的功能。配置文件中的bean的信息是被加载在HashMap中的,一个..._ssm那个文件是运行
计算机的外围设备简介_计算机外围固定-程序员宅基地
文章浏览阅读6.1k次,点赞3次,收藏5次。外围设备介绍计算机的外围设备(简称外设)虽然很多,但按功能分大类只有四类:输入、输出、存储、网络通讯。有些专业计算机需要的外围设备也不尽相同,并不都需要这四类外围设备。外围设备可以按需要组装,有些专业计算机甚至可以将存储设备和主芯片集成到一片芯片上,从而不再需要外加存储设备。最早的计算机(那时还只能称为计算器,只能做简单运算,如ABC机和ENIAC机)输入只是一些拨码开关,只能输入数字(还得是二进_计算机外围固定
java 图片中加文字_java怎么在图片上加文字-程序员宅基地
文章浏览阅读1.5k次。java 图片中加文字_java怎么在图片上加文字
GBase8cGDCA认证模拟题题库(三)_如果需要打开delete语句的审计功能,需要开启下面哪个参数-程序员宅基地
文章浏览阅读720次,点赞20次,收藏6次。B 选项,在创建模式时,可以不指定模式名。C 选项,兼容模式可选值为 AB、C、PG.安装GBase 8c分布式集群时所需的配置文件gbase.yml,在解压GBase8cV5 S3.0.0BXX CentOS x86 64.tar.bz2压缩包生成的目录中得到。真值的有效文本值是: TRUE、t、"true'、y、yes'、"1'TRUE'、true、整数范围内1~2^63-1、整数范围内-1~-2^63。GBase 8c 使用create table 创建表时,不指定参数,默认是astore,行存表。_如果需要打开delete语句的审计功能,需要开启下面哪个参数
随便推点
rem和vw的分析比较_rem和vw兼容性-程序员宅基地
文章浏览阅读6.5k次,点赞3次,收藏9次。rem:首先rem是css单位,相比于px固定的像素单位,rem是相对像素单位,更加的灵活。需求存在:现在移动端各种屏幕的出现,适应性就更加的强烈。根据分辨率的不同让html的字体大小变化。一、基本原理:我们在页面中写rem,由于rem是相对于根元素字体大小来计算的,那么就可以实现自适应的效果。Rem原理举例:设计稿宽度:x px移动设备宽度:y pxHtml中font-size..._rem和vw兼容性
【Ubuntu】Ubuntu 20.04安装Python3.7_ubuntu server 20.04 完整安装python3.7-程序员宅基地
文章浏览阅读1.6w次,点赞5次,收藏81次。注意:转入root权限下1. 升级# sudo apt update# sudo apt upgrade -y2. 安装编译Python源程序所需的包# sudo apt install build-essential -y# sudo apt install libncurses5-dev libgdbm-dev libnss3-dev libssl-dev libreadline-dev libffi-dev -y# sudo apt-get install zlib1g-dev._ubuntu server 20.04 完整安装python3.7
matlab建模DNA双链,PPT绘制科研图形—DNA双链、分子细胞模型-程序员宅基地
文章浏览阅读1.3k次。原标题:PPT绘制科研图形—DNA双链、分子细胞模型 PPT绘制DNA双链 1用矩形工具画一个矩形如下,线条颜色设置为无,填充色如下图蓝色 2选中矩形框,选择菜单栏的“格式—— 编辑形状——转换为任意多边形” 3这个时候再看下“编辑形状”,可以看到“编辑顶点” 已经为可用状态 4点击“编辑顶点“,矩形框四个角变为黑色实点。可以拖动实点变为如下图示。然后在边缘上右键,选择”添加顶点“,添加如下顶点 ..._matlab双螺旋结构模型图怎么画
duilib vs2015 安装_DuiLib(1)——简单的win32窗口-程序员宅基地
文章浏览阅读169次。资源下载https://yunpan.cn/cqF6icWRN5CTc 访问密码 92e3 注:DUILIB库.7z 是vs2015下编译好的动态库及静态库,如上图所示一、新建一个win32工程项目设置中选择:debug,常规中:全程无优化-全程无优化,多线程调试 (/MTd);我的项目选择的是静态编译,使用的是静态库,就不需要带duilib.dll文件了代码如下:#include #inclu..._vs2015使用duilib
OpenGL: 渲染管线理论详解_通过此次实验你对固定渲染管线的opengl编程有什么了解。-程序员宅基地
文章浏览阅读5k次,点赞4次,收藏13次。学习着色器,并理解着色器的工作机制,就要对OpenGL的固定功能管线有深入的了解。首先要知道几个OpenGL的术语:渲染(rendering):计算机根据模型(model)创建图像的过程。模型(model):根据几何图元创建的物体(object)。几何图元:包括点、直线和多边形等,它是通过顶点(vertex)指定的。 最终完成了渲染的图像是由在屏幕上绘制的像素组成的。在内存中,和像素有关的信息(如像素的颜色)组织成位平面的形式,位平面是一块内存区域,保存了屏幕上每个像素的一个位的信息。_通过此次实验你对固定渲染管线的opengl编程有什么了解。
Android MPAndroidChart:动态添加统计数据线【8】_android 动态统计-程序员宅基地
文章浏览阅读3.9k次。Android MPAndroidChart:动态添加统计数据线【8】本文在附录相关文章6的基础上,动态的依次增加若干条统计折线(相当于批量增加数据点)。布局文件: