Pix2PixHD 阅读笔记(翻译)_cave和pix2pixhd结合-程序员宅基地
High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs
作者:Ting-Chun Wang{NVIDIA}, Ming-Y u Liu{NVIDIA}, Jun-Yan Zhu{UC Berkeley}, Andrew Tao{NVIDIA}, Jan Kautz{NVIDIA}, Bryan Catanzaro{NVIDIA}
会议:CVPR2018
论文链接:https://arxiv.org/abs/1711.11585
代码链接:https://github.com/NVIDIA/pix2pixHD
动机:图像到图像的翻译是GAN的一个重要应用,表示基于输入图像生成指定的输出图像的过程,比如有监督的pix2pix,无监督的CycleGAN等。而基于语义分割图生成对应图像可以看做是图像到图像的翻译中的一个特例,这个研究方向主要有2个发展趋势:1、生成的图像要尽可能接近真实图像;2、生成图像的分辨率越来越大,也就是越来越往高清大图发展。
这篇发表在CVPR2018的pix2pixHD在这两个方面都有不错的贡献。pix2pixHD是在pix2pix算法基础上做了优化,pix2pix算法合成图像的分辨率在256 × 256左右,作者曾经尝试直接用pix2pix算法生成高分辨率图像,但是发现训练过程不稳定,效果也不好,因此才不断优化得到pix2pixHD。pix2pixHD的训练依然是有监督的,也就是需要pair对的数据。

Abstract
我们基于Conditional GANs提出了一种从语义图上合成高分辨率逼真图像的方法。在这项工作中,我们生成了2048 × 1024分辨率的视觉上吸引人的结果,具有新颖的对抗损失,以及新的多尺度发生器和鉴别器架构。此外,我们将框架扩展到具有两个附加特征的交互式视觉操作。首先,我们合并了对象实例分割信息(object instance segmentation information),它支持对象级别的操作,如移除/添加对象和更改对象类别。其次,我们提出了一种方法可以在给定相同输入的情况下生成不同的结果,允许用户交互式地编辑对象外观。我们的方法明显优于现有方法,提高了深度图像合成和编辑的质量与分辨率。
1. Introduction
图像渲染是一件很费时费力的事情,但是我们可以通过训练模型来自动渲染,使得渲染变得简单。
使用语义分割方法,我们可以将图像转换到语义标签域,编辑标签域中的对象,然后将它们转换回图像域。这种方法还为我们提供了更高级别的图像编辑新工具,例如,向图像添加对象或更改现有对象的外观。
为了从语义标签中合成图像,可以使用pix2pix方法,这是一种图像到图像的翻译框架[21],它在条件设置中利用了GANs[16]。最近,Chen和Koltun[5]提出,对抗训练对于高分辨率图像生成任务来说可能是不稳定和容易失败的。取而代之的是,他们采用一种改进的感知损失(a modified perceptual loss)[11,13,22]来合成图像,这些图像分辨率很高,但往往缺乏精细的细节和逼真的纹理。
**在这里,我们解决了上述最新方法的两个主要问题:(1)用GANs生成高分辨率图像的困难[21]和(2)在以前的高分辨率结果中缺乏细节和真实纹理[5]。**我们表明,通过一个新的、鲁棒的对抗学习目标以及新的多尺度生成器和鉴别器架构,我们可以合成分辨率为2048 × 1024分辨率的逼真图像,这些图像比以前方法计算的结果更具视觉吸引力[5,21]。我们首先仅通过对抗性训练获得结果,而不依赖任何hand-crafted的损失[44]或预先训练的感知损失网络(例如VGGNet[48])[11,22](图9c,10b)。然后,我们展示出,在某些情况下,如果有一个预先训练的网络[48],增加感知损失可以略微改善结果(图9d, 10c)。在图像质量方面,这两个结果都大大优于以前的工作。
此外,为了支持交互式的语义操作,我们从两个方向扩展了我们的方法。首先,我们使用实例级对象分割信息,它可以在同一类别中分离不同的对象实例。它支持灵活的对象操作,如添加/删除对象和更改对象类型。其次,我们提出一种方法来生成给定相同输入标签映射的不同结果,允许用户交互式地编辑相同对象的外观。
我们与最先进的视觉合成系统进行了比较[5,21],结果表明,我们的方法在定量评估和人类感知研究方面都优于这些方法。我们还对训练目标和实例级分割信息(instance-level segmentation information)的重要性进行了消融研究。除了语义操作之外,我们还在edge2photo应用程序上测试了我们的方法(图2、13),这显示了我们方法的泛化性。代码和数据可以在我们的网站上找到。

2. Related Work
Generative adversarial networks 受他们成功的启发,我们提出了一种新的从粗到细的生成器和多尺度鉴别器架构,适合于以更高分辨率的条件生成图像。
Image-to-image translation
Deep visual manipulation
3. Instance-Level Image Synthesis
我们首先回顾基模型pix2pix(第3.1节)。然后,我们描述如何通过改进的目标函数和网络设计来提高结果的真实感和分辨率(第3.2节)。接下来,我们使用额外的实例级对象语义信息来进一步提高图像质量(第3.3节)。最后,我们介绍了一个实例级特征embedding方案,以更好地处理图像合成的多模态特性,从而实现交互式对象编辑(第3.4节)。
3.1. The pix2pix Baseline
pix2pix方法[21]是一个用于图像到图像翻译的条件GAN框架。它由一个生成器G和一个判别器D组成。在我们的任务中,生成器G的目标是将语义标签映射翻译成真实的图像,而判别器D的目标是将真实图像从翻译后的图像中区分出来。训练过程是有监督的,也就是说,训练集是一系列的图像pairs { ( s i , x i ) } \{(s_i,x_i)\} {
(si,xi)},其中 s i s_i si为语义标签映射, x i x_i xi为对应的自然照片。条件GANs的目的是通过极小极大博弈来模拟给定输入语义标签映射的真实图像的条件分布:

其中目标函数 L G A N ( G , D ) L_{GAN}(G,D) LGAN(G,D)为

pix2pix方法采用U-Net[43]作为生成器,patch-based的全卷积网络[36]作为判别器。对判别器的输入是语义标签映射和相应图像的通道级的联接。但是,在Cityscapes[7]上生成的图像分辨率最高达256 × 256。我们直接使用pix2pix框架进行测试,生成高分辨率的图像,但发现训练不稳定,生成的图像质量不令人满意。因此,我们将在下一小节中描述如何改进pix2pix框架。
3.2. Improving Photorealism and Resolution
我们通过使用一个从粗到细的生成器、一个多尺度的鉴别器结构和一个鲁棒的对抗学习目标函数来改进pix2pix框架。
Coarse-to-fine generator 我们将生成器分解成两个子网络:G1和G2。我们将G1称为全局生成网络,G2称为局部增强网络。生成器为G = {G1, G2},由图3所示。全局生成器网络以1024 × 512的分辨率的图像为输入运行,而局部增强网络输出分辨率为前一图像输出尺寸的4×图像(沿着每个图像维度的2×)。为了以更高的分辨率合成图像,可以增加其他局部增强网络。例如,生成器G = {G1, G2}的输出图像分辨率为2048×1024, G = {G1, G2, G3}的输出图像分辨率为4096 × 2048。

我们的全局生成器是建立在Johnson et al.[22]提出的架构之上的,该架构已被证明可以成功地在512 × 512的图像上进行元风格的迁移(neural style transfer)。它由3个部分组成:一个卷积前端(convolutional front-end) G 1 ( F ) G^{(F)}_1 G1(F),一组残差块(residual blocks) G 1 ( R ) G^{(R)}_1 G1(R)[18],以及一个转置的卷积后端(transposed convolutional back-end) G 1 ( B ) G^{(B)}_1 G1(B)。将分辨率为1024×512的语义标签映射依次传递给3个分量,输出分辨率为1024×512的图像。
局部增强网络也由3个部分组成:卷积前端 G 2 ( F ) G^{(F)}_2 G2(F),一组残差块 G 2 ( R ) G^{(R)}_2 G2(R),以及一个转置的卷积后端 G 2 ( B ) G^{(B)}_2 G2(B)。输入标签映射到G2的分辨率是2048 × 1024。与全局生成器网络不同,残差块 G 2 ( R ) G^{(R)}_2 G2(R)的输入是两个特征图的元素之和(element-wise),分别是 G 2 ( F ) G^{(F)}_2 G2(F)的输出特征图和全局生成网络 G 1 ( B ) G^{(B)}_1 G1(B)的后端最后一个特征图。这有助于集成从G1到G2的全局信息。(也就是从粗到细的过程)
在训练过程中,我们首先训练全局生成器,然后按照它们的分辨率顺序训练局部增强器。然后我们一起对所有的网络进行微调。我们使用这种生成器设计来有效地聚合全局和局部信息以完成图像合成任务。我们注意到,这样的多分辨率管道在计算机视觉[4]中是一个很好的实践,而两尺度通常足够[3]。在最近的无条件GANs[9,19]和条件映像生成[5,57]中可以发现类似但不同的架构。
Multi-scale discriminators 高分辨率图像合成对GAN鉴别器的设计提出了重大挑战。为了区分高分辨率的真实图像与合成图像,鉴别器需要有较大的感受野。这将需要更深的网络或更大的卷积核,这两者都将增加网络容量,并可能导致过拟合。此外,这两种选择都需要更大的训练内存,然而内存是高分辨率图像生成的稀缺资源。
为了解决这一问题,我们提出使用多尺度鉴别器。我们使用的3个鉴别器具有相同的网络结构,但在不同的图像尺度上运作。我们将判别器称为D1, D2和D3。具体来说,我们对真实和合成的高分辨率图像进行了2倍和4倍的降采样,以创建3个尺度的图像金字塔。然后将判别器D1、D2和D3分别在3个不同尺度上进行训练区分真实图像与合成图像。虽然这些鉴别器有相同的结构,但在最粗尺度上运作的那一个具有最大的感受野。它有一个更全局的图像视图,并可以指导生成器生成全局一致的图像。另一方面,在最精细尺度上的鉴别器鼓励生成器产生更精细的细节。这也使得训练从粗到细的生成器变得更容易,因为扩展一个低分辨率模型到一个更高分辨率模型只需要在最精细级别上添加一个鉴别器,而不是从头再训练。在没有多尺度判别器的情况下,我们观察到生成的图像中经常出现许多重复的图案。
有了这些判别器,Eq.(1)中的学习问题就变成了多任务的学习问题

在无条件GAN[12]中,提出了在同一图像尺度下使用多个GAN鉴别器。Iizuka等[20]将全局图像分类器添加到条件GANs中,综合全局一致内容进行修复。在这里,我们设计扩展到不同图像尺度的多个鉴别器,以对高分辨率图像进行建模。
Improved adversarial loss 我们通过结合基于鉴别器的特征匹配损失来改善Eq.(2)中的GAN损失。这种损失稳定了训练,因为生成器必须在多个尺度上产生自然分布。具体来说,我们从多层鉴别器中提取特征,并学习匹配真实图像和合成图像中的这些中间表征。为便于表示,我们将鉴别器 D k D_k Dk 中第 i i i层的特征提取器表示为 D k ( i ) D^{(i)}_k Dk(i)(从输入到 D k D_k Dk的第 i i i层)。计算特征匹配损失 L F M ( G , D k ) L_{FM}(G, D_k) LFM(G,Dk)为:

其中T为层数, N i N_i Ni为每层的元素数。我们的GAN鉴别器特征匹配损失与感知损失有关[11,13,22],这已被证明对图像超分辨率[32]和样式转移[22]有用。在实验中,我们讨论了如何将鉴别器特征匹配损失和感知损失联合使用来进一步提高性能。我们注意到VAE-GANs[30]也有类似的损失。
我们的全部目标包括GAN损失和特征匹配损失:

λ控制这两项的重要程度。注意,对于特征匹配损失 L F M L_{FM} LFM, D k D_k Dk只能作为特征提取器,而不能最大化损失 L F M L_{FM} LFM。(意思应该就是 L F M L_{FM} LFM只用来改生成器的参数吧?)
3.3. Using Instance Maps
现有的图像合成方法仅利用语义标签映射[5,21,25],即每个像素值代表像素的对象类*(意思就是不同颜色对应着不同类)*。这种映射不能区分同一类别的物体。另一方面,实例级语义标签映射为每个单独的对象包含一个惟一的对象ID。要合并实例映射,可以直接将其传递到网络,或将其编码为一个one-hot向量。然而,这两种方法在实践中都很难实现,因为不同的图像可能包含不同数量的同一类别的对象。或者,可以为每个类预先分配固定数量的通道(例如,10个),但是如果通道数量设置得太小,这个方法就会失败,如果通道数量太大,就会浪费内存。
相反,我们认为实例映射提供的最关键的信息是对象边界,这在语义标签映射中是不可用的。例如,当同一个类的对象彼此相邻时,仅通过语义标签映射无法区分它们。在街景中尤其如此,因为许多停放的汽车或行走的行人往往是挨着的,如图4a所示。但是,有了实例映射,分离这些对象就变得更容易了。

因此,为了提取这个信息,我们首先计算实例边界图(图4b)。在我们的实现中,如果对象ID与它的4个邻居中的任何一个不同,那么实例边界映射中的像素为1,否则为0。然后,将实例边界映射与语义标签映射的one-hot向量进行连接,并输入生成器网络。同样,对判别器的输入是实例边界映射、语义标签映射和真实/合成图像的通道级联。图5b展示了一个示例,演示了使用对象边界的改进。在第4节中,我们还展示了用实例边界地图训练的模型,可以呈现出更逼真的对象边界。

3.4. Learning an Instance-level Feature Embedding
基于语义标号标签的图像合成是一个单对多的映射问题。理想的图像合成算法应该能够使用相同的语义标签地图生成不同的、真实的图像。最近,一些作品学习了在给定相同输入的情况下产生固定数量的离散输出[5,15]或合成由编码整个图像的潜向量控制的不同模式[66]。尽管这些方法解决了多模态图像合成问题,但不适合我们的图像处理任务,主要有两个原因。首先,用户无法直观地控制模型会生成哪种图像[5,15]。其次,这些方法关注全局颜色和纹理变化,不允许对生成的内容进行对象级别的控制。
为了生成不同的图像并允许实例级控制,我们提出添加额外的低维特征通道作为生成网络的输入。我们展示了,通过操纵这些特征,可以灵活地控制图像合成过程。此外,请注意,由于特征通道是连续量,因此我们的模型原则上可以生成无限多的图像。
为了生成低维特征,我们训练一个编码器网络E,为图像中的每个实例寻找与真实目标相对应的低维特征向量。我们的特征编码器架构是一个标准的编码器-解码器网络。为了确保每个实例中的特征是一致的,我们在编码器的输出中添加了一个实例的平均池化层来计算对象实例的平均特征。然后将平均特征广播到实例的所有像素位置。图6显示了编码特征的示例。

我们将式(5)中的G(s)替换为G(s, E(x)),并与生成器和判别器共同训练编码器。编码器训练完成后,我们在训练图像中的所有实例上运行它,并记录得到的特征。然后对每个语义类别的特征进行K-means聚类。因此,每一组都为特定的风格编码特征,例如,道路的沥青或鹅卵石纹理。在inference时,我们随机选择一个聚类中心,并使用它作为编码后的特征。这些特征与标签映射连接起来,并用作生成器的输入。我们试图在特征空间上使用KullbackLeibler loss[28],以获得更好的test-time采样[66],但发现这需要用户直接调整每个对象的潜向量。相反,我们为每个对象实例提供了K种模式供用户选择。(看他给的视频,应该是将数据集种与该实例最相似的K个实例,给用户选择以生成不同的图像)
4. Results
我们首先在第4.1节中对领先的方法进行了定量比较。然后,我们在第4.2节报告了一项主观的人类知觉研究。最后,我们将在第4.3节展示几个交互式对象编辑结果的例子。
Implementation details 我们使用LSGANs[37]进行稳定的训练。在所有的实验中,我们设置权重$λ = 10 ( E q . ( 5 ) ) 和 (Eq.(5))和 (Eq.(5))和K = 10 的 K − m e a n s 。 我 们 使 用 三 维 向 量 为 每 个 对 象 实 例 编 码 特 征 。 我 们 实 验 添 加 一 个 感 知 损 失 的K-means。我们使用三维向量为每个对象实例编码特征。我们实验添加一个感知损失 的K−means。我们使用三维向量为每个对象实例编码特征。我们实验添加一个感知损失λ \sum_{i=1}^N \frac{1}{M_i}[||F{(i)}(x)−F{(i)}(G(s))||_1] 到 我 们 的 目 标 ( E q . ( 5 ) ) , 其 中 到我们的目标(Eq.(5)),其中 到我们的目标(Eq.(5)),其中λ = 10 , F ( i ) 表 示 V G G 网 络 带 有 , F(i)表示VGG网络带有 ,F(i)表示VGG网络带有M_i$个元素的第i层。我们观察到,这种损失使结果略有改善。我们将这两种变量命名为 ours 和 ours(不带VGG损失,w/o VGG loss)。请在附录中找到更多的训练和架构细节。
Datasets 我们对Cityscapes数据集[7]和NYU Indoor RGBD数据集[40]进行了广泛的比较和消融研究。我们报告了ADE20K数据集[63]和Helen Face数据集[31,49]的其他定性结果。
Baselines 我们与两种最先进的算法进行了比较:pix2pix[21]和CRN[5]。我们使用默认设置在高分辨率图像上训练pix2pix模型。我们通过作者公开提供的模型产生高分辨率的CRN图像。
4.1. Quantitative Comparisons
我们采用与以前的图像-图像翻译算法相同的评价标准[21,65]。为了量化结果的质量,我们对合成的图像进行语义分割,并比较预测的片段与输入的匹配程度。直觉是,如果我们能够产生与输入标签映射相对应的真实图像,那么一个现成的语义分割模型(如我们使用的PSPNet[61])应该能够对生成图像预测出真实的标签。表1报告了计算的分割精度。可以看出,无论是像素精度还是IoU(intersection-over-union),我们的方法都比其他方法有很大的优势。而且,我们的结果与原始图像的结果非常接近,这是我们所能达到现实的理论“上限”。这证明了我们算法的优越性。

4.2. Human Perceptual Study
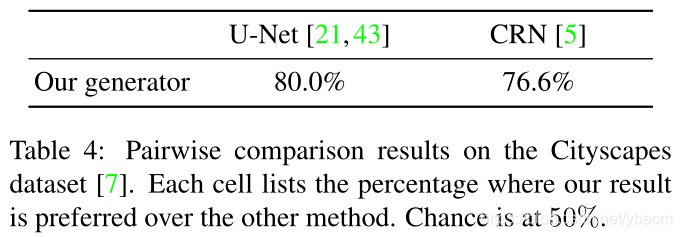
我们进一步通过人类的主观研究来评估我们的算法。我们在cityscape数据集[7]上执行部署在Amazon Mechanical Turk (MTurk)平台上的成对A/B测试。我们遵循与Chen和Koltun[5]中描述的相同的实验步骤。具体来说,我们进行了两种不同的实验:无限制时间和有限时间。





Analysis of the loss function 我们在unlimited time实验中也对比了每个目标函数的重要性,使用了两种损失(1)只有GAN损失,(2)GAN+特征匹配损失(没有VGG损失)。结果是添加特征匹配损失可以明显提升性能,而增加感知损失也能增强结果,但不是很显著(如图9c,10b)。
Using instance maps
Analysis of the generator

Analysis of the discriminator

Additional datasets

4.3. Interactive Object Editing

5. Discussion and Conclusion
整体来看,pix2pixHD在pix2pix的基础上主要做了4个方面的改进:1、生成器从U-Net升级为多级生成器(coarse-to-fine generator)。2、判别器从patch GAN升级为多尺度判别器(multi-scale discriminator)。3、优化目标上增加了基于判别器特征的匹配损失。4、增加实例级别的信息。
参考:
智能推荐
在Google使用Borg进行大规模集群的管理 7-8-程序员宅基地
文章浏览阅读606次。为什么80%的码农都做不了架构师?>>> ..._google trace batch job
python加密字符串小写字母循环后错两位_python学习:实现将字符串进行加密-程序员宅基地
文章浏览阅读2.6k次,点赞3次,收藏3次。'''题目描述1、对输入的字符串进行加解密,并输出。2加密方法为:当内容是英文字母时则用该英文字母的后一个字母替换,同时字母变换大小写,如字母a时则替换为B;字母Z时则替换为a;当内容是数字时则把该数字加1,如0替换1,1替换2,9替换0;其他字符不做变化。s'''#-*-coding:utf-8-*-importre#判断是否是字母defisLetter(letter):iflen..._编写函数fun2实现字符串加密,加密规则为:如果是字母,将其进行大小写转换;如果
【Java容器源码】集合应用总结:迭代器&批量操作&线程安全问题_迭代器是否可以保证容器删除和修改安全操作-程序员宅基地
文章浏览阅读4.4k次,点赞6次,收藏8次。下面列出了所有集合的类图:每个接口做的事情非常明确,比如 Serializable,只负责序列化,Cloneable 只负责拷贝,Map 只负责定义 Map 的接口,整个图看起来虽然接口众多,但职责都很清晰;复杂功能通过接口的继承来实现,比如 ArrayList 通过实现了 Serializable、Cloneable、RandomAccess、AbstractList、List 等接口,从而拥有了序列化、拷贝、对数组各种操作定义等各种功能;上述类图只能看见继承的关系,组合的关系还看不出来,比如说_迭代器是否可以保证容器删除和修改安全操作
养老金融:编织中国老龄社会的金色安全网
在科技金融、绿色金融、普惠金融、养老金融、数字金融这“五篇大文章”中,养老金融以其独特的社会价值和深远影响,占据着不可或缺的地位。通过政策引导与市场机制的双重驱动,激发金融机构创新养老服务产品,如推出更多针对不同年龄层、风险偏好的个性化养老金融产品,不仅能提高金融服务的可获得性,还能增强民众对养老规划的主动参与度,从而逐步建立起适应中国国情、满足人民期待的养老金融服务体系。在人口老龄化的全球趋势下,中国养老金融的发展不仅仅是经济议题,更关乎社会的稳定与进步。养老金融:民生之需,国计之重。
iOS 创建开源库时如何使用图片和xib资源
在需要使用图片的地方使用下面的代码,注意xib可以直接设置图片。将相应的图片资源文件放到bundle文件中。
R语言学习笔记9_多元统计分析介绍_r语言多元统计分析-程序员宅基地
文章浏览阅读3.6k次,点赞4次,收藏66次。目录九、多元统计分析介绍九、多元统计分析介绍_r语言多元统计分析
随便推点
基于psk和dpsk的matlab仿真,MATLAB课程设计-基于PSK和DPSK的matlab仿真-程序员宅基地
文章浏览阅读623次。MATLAB课程设计-基于PSK和DPSK的matlab仿真 (41页) 本资源提供全文预览,点击全文预览即可全文预览,如果喜欢文档就下载吧,查找使用更方便哦!9.90 积分武汉理工大学MATLAB课程设计.目录摘要 1Abstract 21.设计目的与要求 32.方案的选择 42.1调制部分 42.2解调部分 43.单元电路原理和设计 63.1PCM编码原理及设计 63.1.1PCM编码原理 ..._通信原理课程设计(基于matlab的psk,dpsk仿真)(五篇模版)
腾讯微搭小程序获取微信用户信息_微搭 用微信号登录-程序员宅基地
文章浏览阅读3.5k次,点赞6次,收藏28次。腾讯微搭小程序获取微信用户信息无论你对低代码开发的爱与恨, 微信生态的强大毋庸置疑. 因此熟悉微搭技术还是很有必要的! 在大多数应用中, 都需要获取和跟踪用户信息. 本文就微搭中如何获取和存储用户信息进行详细演示, 因为用户信息的获取和存储是应用的基础.一. 微搭每个微搭平台都宣称使用微搭平台可以简单拖拽即可生成一个应用, 这种说法我认为是"夸大其词". 其实微搭优点大致来说, 前端定义了很多组件, 为开发人员封装组件节省了大量的时间,这是其一; 其二对后端开发来说, 省去了服务器的部署(并没有省去后_微搭 用微信号登录
sql中索引的使用分析
sql中索引的使用分析
termux安装metasploit()-程序员宅基地
文章浏览阅读8.9k次,点赞16次,收藏108次。因为呢,termux作者,不希望让termux变成脚本小子的黑客工具,于是把msf , sqlmap等包删了。至于如何安装metasploit呢。apt update -y && apt upgrade -y #更新升级更新升级之后要安装一个叫 git 的安装包apt install git -y然后我们就开始//这里的话建议把手机放到路由器旁边,保持网络的优良。或者科学上网。//git clone https://github.com/gushmazuko/metaspl_termux安装metasploit
armbian docker Chrome_一起学docker06-docker网络-程序员宅基地
文章浏览阅读141次。一、Docker支持4种网络模式Bridge(默认)--network默认网络,Docker启动后创建一个docker0网桥,默认创建的容器也是添加到这个网桥中;IP地址段是172.17.0.1/16 独立名称空间 docker0桥,虚拟网桥的工作方式和物理交换机类似,这样主机上的所有容器就通过交换机连在了一个二层网络中。host容器不会获得一个独立的network namespace,而是与宿主..._armbian 172.17.0.1
Ansible-Tower安装破解
Ansible-Tower安装破解。