大数据:聚类算法深度解析-程序员宅基地
文章目录
深度解析大数据聚类分析
大数据聚类分析是数据科学领域中的关键技术之一,它能够帮助我们从庞大而复杂的数据集中提取有意义的信息和模式。在这篇博文中,我们将深入探讨大数据聚类分析的概念、方法、应用和挑战。
1. 聚类分析的基本概念
1.1 什么是聚类分析?
聚类分析是一种将数据分成具有相似特征的组的技术。其目标是使组内的数据点相似度最大化,而组间的相似度最小化。这有助于发现数据中的隐藏结构和模式,为进一步的分析和决策提供基础。
在聚类分析中,我们将数据点划分为不同的簇,使得同一簇内的数据点相互之间更为相似。这种相似性是通过一定的距离度量来定义的,常见的包括欧氏距离、曼哈顿距离等。而组间的相似度最小化,则意味着不同簇之间的差异性较大。
聚类的过程类似于将一堆未标记的数据分成若干组,使得同一组内的数据点更加相似,例如下面分类结果。
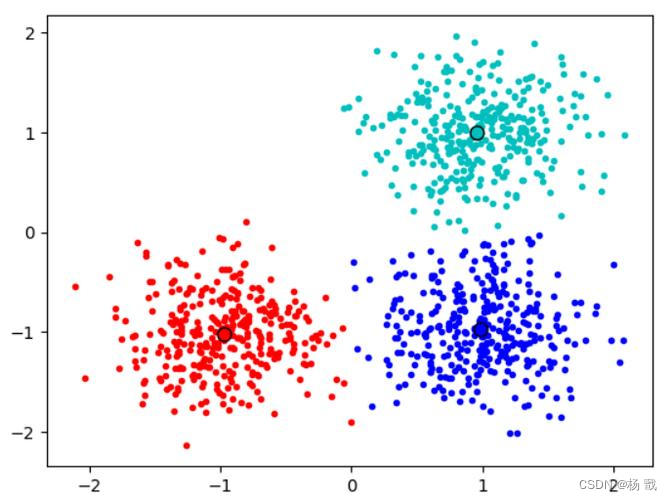
这有助于我们在没有先验标签的情况下发现数据中的潜在结构,为后续的分析和应用提供了基础。
# 伪代码:K均值算法实现聚类分析
from sklearn.cluster import KMeans
import numpy as np
# 假设有一组数据 points,其中每一行代表一个数据点的特征
points = np.array([[1, 2], [5, 8], [1.5, 1.8], [8, 8], [1, 0.6], [9, 11]])
# 假设我们要将数据分成两个簇
kmeans = KMeans(n_clusters=2)
kmeans.fit(points)
# 获取每个数据点所属的簇
labels = kmeans.labels_
# 输出结果
print("数据点所属簇:", labels)
在上述代码中,我们使用了K均值算法对一组数据进行聚类分析。该算法将数据点划分为两个簇,输出每个数据点所属的簇。这就是聚类分析的基本原理之一。
聚类分析的应用非常广泛,从市场细分到图像分割,都离不开聚类的帮助。通过深入理解聚类分析的概念和方法,我们能够更好地应用它来解决实际问题。
1.2 大数据背景下的挑战
在大数据背景下,数据量巨大、多样性高、实时性要求等因素给聚类分析带来了巨大的挑战。传统的聚类算法可能无法有效处理这些庞大的数据集,因此需要采用分布式计算和更高效的算法来应对这些挑战。
1.2.1 数据量巨大
大数据的特点之一是其庞大的数据量,传统的单机计算无法处理如此大规模的数据。对于聚类分析而言,这就要求我们使用分布式计算框架,如Apache Spark,以同时处理并行计算,提高处理效率。

1.2.2 多样性高
大数据往往涉及多种类型的数据,包括结构化数据、半结构化数据和非结构化数据。传统聚类算法可能只适用于特定类型的数据,因此需要采用更灵活的算法或者组合多种算法来处理这种多样性。
1.2.3 实时性要求
在大数据背景下,很多应用场景要求对数据进行实时的聚类分析。例如,在在线广告投放中,需要实时了解用户的兴趣以提供更精准的广告。因此,聚类算法不仅需要高效处理大规模数据,还需要具备实时性能。
为了解决这些挑战,大数据聚类分析引入了诸如流式计算、近似算法和增量式计算等技术。下面是一个简单的流式聚类的示例:
# 伪代码:流式聚类示例
from sklearn.cluster import MiniBatchKMeans
import numpy as np
# 初始化MiniBatchKMeans模型
mbk = MiniBatchKMeans(n_clusters=3, random_state=42)
# 模拟流式数据输入
streaming_data = np.array([[1, 2], [5, 8], [1.5, 1.8], [8, 8], [1, 0.6], [9, 11]])
# 逐步更新聚类模型
for i in range(len(streaming_data)):
mbk.partial_fit([streaming_data[i]])
# 获取聚类结果
labels = mbk.labels_
print("数据点所属簇:", labels)
在上述示例中,我们使用了MiniBatchKMeans模型来模拟流式数据输入,并逐步更新聚类模型。这种方式使得算法能够在数据流不断到来的情况下进行实时聚类。
通过克服大数据背景下的这些挑战,我们可以更好地应用聚类分析在复杂和庞大的数据集中发现有价值的模式和信息。
2. 大数据聚类算法
2.1 K均值算法
K均值是最常用的聚类算法之一,它通过将数据点分配到K个簇,使得簇内的数据点尽量相似。该算法迭代进行簇分配和簇中心更新,直至收敛。在大数据背景下,可以使用分布式计算框架如Apache Spark来加速计算过程。
K均值算法步骤:
- 初始化: 随机选择K个数据点作为初始簇中心。
- 分配: 将每个数据点分配到距离最近的簇中心。
- 更新: 重新计算每个簇的中心,即取簇中所有数据点的平均值。
- 重复: 重复步骤2和步骤3,直至簇中心不再发生明显变化或达到预定迭代次数。
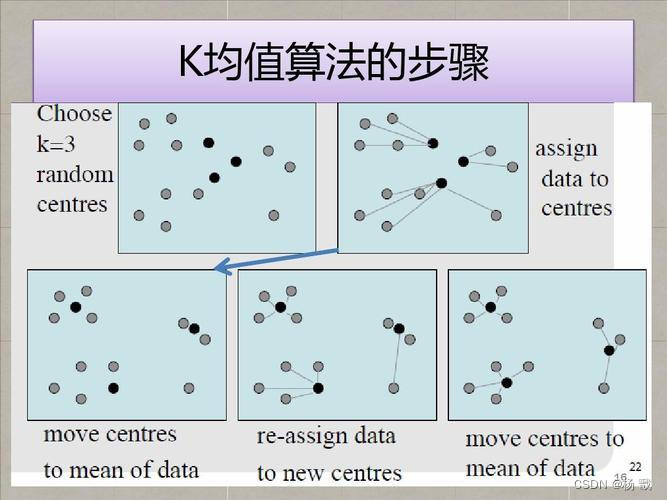
K均值算法的优点之一是其简单性和易于理解。然而,在大数据背景下,传统的K均值算法可能面临计算效率低下的问题。因此,我们可以借助分布式计算框架来提高其处理大规模数据的能力。
# 伪代码:K均值算法在Apache Spark中的实现
from pyspark.ml.clustering import KMeans
# 假设data是一个大数据集的DataFrame
kme智能推荐
app加急审核-程序员宅基地
文章浏览阅读55次。原文地址:http://www.cnblogs.com/Twisted-Fate/p/4915184.html最近公司app由于疏忽审核被拒绝了,但是计划是最近两天上线时间紧急,希望能快速审核上线,了解到淘宝里面有加速商店,但是价格真是黑心,首次上线12000元,APP若已经上线的更新5999,据网上了解他们也是编写加急理由,已经无法忍受这种坑爹的赚钱方式,总结了一些加急经历的给与建议,..._加急审app
linux 中的source命令_linux中的source指令-程序员宅基地
文章浏览阅读2.1k次。linux 中的source命令source命令是bash中的内建命令,它等同于点命令(.),用于读取和在当前shell环境中执行指定文件中的命令,执行完毕之后退出码为该文件中的最后一个命令的退出码,指定的文件可以没有执行权限(没有权限是指该文件没有rwx中x的权限,也就是可执行到权限,这里到意思是说,即使该文件没有可执行权限,通过source也可以执行他)。在当前shell中执行(s_linux中的source指令
jquery 获取子 div_jq 子级别div-程序员宅基地
文章浏览阅读908次。获取 dom 对象$("#divId").children("div").get(0);$("#divId").children("div")[0];获取 jquery 对象$("#divId").children("div").eq(0);$($("#divId").children("div").get(0));【Java面试题与答案】整理推荐基础..._jq 子级别div
基于Springboot + vue实现的交通管理在线服务系统-程序员宅基地
文章浏览阅读271次,点赞4次,收藏4次。管理员管理:负责添加、删除、修改管理员账号,并设置相应的权限,确保管理员团队的专业性和高效性。新闻信息管理:发布、编辑和删除交通新闻、政策更新、路况信息等,保持信息的实时性和有效性。驾驶证业务管理:在线提交驾驶证申请、查询、更新、补办等业务,并实时查看办理进度。新闻信息查看:浏览系统发布的交通新闻、政策更新、路况信息等,了解最新的交通动态。机动车业务管理:在线提交车辆注册、年检、转移、报废等业务申请,并获取办理结果。用户管理:管理用户账号,包括用户注册、登录、权限设置等,确保系统的安全性。
打印系统开发(42)——静默打印_静默打印是什么意思-程序员宅基地
文章浏览阅读4.4k次。1.问题描述希望每次打印时,都是用固定的打印机打印并且不希望弹出对话框进行设置,此时便可以设置静默打印。1.1什么是静默打印静默打印即点击打印时不弹出选项窗口和打印机设置窗口直接进行打印。1.2支持静默打印的打印方式零客户端打印、本地打印、服务器端打印支持静默打印。2.静默打印设置方法2.1 零客户端打印设置方法注:只支持 IE点击模板-打印..._静默打印是什么意思
STM32+74HC595:带领你10分钟用对74HC595_74hc595连接stm32-程序员宅基地
文章浏览阅读2.4w次,点赞14次,收藏68次。使用的是STM32CBT8,小模块用起来性价比超级高,资源丰富,移植u/COS及HTTP、MQTT协议等等用起来简直欲罢不能,摇摇欲仙!BUT:IO口资源太少了,我想让你驱动100个LED,你缺告诉我,我的要求太多,你满足不了......还好,找到了74HC595,但是网上很多资源讲的我看了半天才总结、提炼并另辟蹊径出来精髓===============================_74hc595连接stm32
随便推点
AssertionError: Torch not compiled with CUDA enabled-程序员宅基地
文章浏览阅读1.7w次,点赞17次,收藏101次。解决问题:AssertionError: Torch not compiled with CUDA enabled_assertionerror: torch not compiled with cuda enabled
Silvaco TCAD 2017 在RedHat6.5 Linux系统的安装教程_silvaco的license更新-程序员宅基地
文章浏览阅读1.5w次,点赞4次,收藏37次。Silvaco TCAD 2017 在RedHat6.5 Linux系统的安装教程很多网友问到关于在Linux系统下安装Silvaco TCAD的问题,这里我整理了最近安装Silvaco的安装方法,前前后后共花六个月的时间研究,无数个深夜在重装中度过,希望看到的网友不要重复我的经历首先感谢网络上各路大神提供的安装方法,相信在Windows环境中很多人都能安装上但苦于Windows下无..._silvaco的license更新
html页面点击按钮上传文件,点击按钮实现文件上传及控制文件上传类型-程序员宅基地
文章浏览阅读4.3k次。1.原生js实现文件上传html部分:上传文件js部分:upload(event) { //代替执行上传功能let it = event.target;$(it).next().click();},UploadFile() { //上传文件let msg = new FormData();msg.append('file', $('#uploadBillsInp')[0].files[0..._formdata.append('enctype', 'multipart/form-data');
Android后台源码,Android8.0的后台Service优化源码解析-程序员宅基地
文章浏览阅读245次。今天在用户的错误列表上看到这么个bugjava.lang.RuntimeException: Unable to start receiver com.anysoft.tyyd.appwidget.PlayAppWidgetProvider:java.lang.IllegalStateException: Not allowed to start service Intent { cmp=com...._to start receiver com.mediatek.engineermode.emstartreceiver: java.lang.secur
深刻对比一下阿里云服务器和腾讯云服务器的优劣和区别_腾讯云与阿里云的优劣-程序员宅基地
文章浏览阅读2.5w次,点赞10次,收藏19次。我来简单对比阿里云服务器和腾讯云服务器的优劣和区别腾讯云相比阿里云优势不明显。阿里云比腾讯云开放的时间更早,辅助系统更完善些,功能更多可用性更强。但腾讯云不是单纯卖云服务的,凡是要接入腾讯的生态(比如微信小程序等)必须得用腾讯云服务器,腾讯云迅速发展壮大。腾讯云也在慢慢完善,大多数应用场景也都能满足,但就是对很多新技术的支持总是比阿里云慢一些,高级的配置定制也少一些。服务器结构不是很复杂的话用......_腾讯云与阿里云的优劣
应用C预处理命令_c 添加预处理命令-程序员宅基地
文章浏览阅读1.6k次。********************************LoongEmbedded******************************** 作者:LoongEmbedded(kandi)时间:2011.10.17类别:C基础************_c 添加预处理命令