实战:HPA(Pod 水平自动伸缩)-2021.11.23_hpa软件-程序员宅基地
技术标签: k8s

目录

实验环境
实验环境:
1、win10,vmwrokstation虚机;
2、k8s集群:3台centos7.6 1810虚机,1个master节点,2个node节点
k8s version:v1.22.2
containerd://1.5.5
实验软件
链接:https://pan.baidu.com/s/1I2oQvi2GC1g5J0vxOBooqg
提取码:59mi
–来自百度网盘超级会员V6的分享
1、基础知识
1.HPA 控制器
在前面的学习中我们使用了一个 kubectl scale 命令可以来实现 Pod 的扩缩容功能,但是这个是完全手动操作的,要应对线上的各种复杂情况,**我们需要能够做到自动化去感知业务,来自动进行扩缩容。**为此,Kubernetes 也为我们提供了这样的一个资源对象:Horizontal Pod Autoscaling(Pod 水平自动伸缩),简称 HPA,HPA 通过监控分析一些控制器控制的所有 Pod 的负载变化情况来确定是否需要调整 Pod 的副本数量,这是 HPA 最基本的原理:
我们可以简单的通过 kubectl autoscale 命令来创建一个 HPA 资源对象,HPA Controller 默认30s轮询一次(可通过 kube-controller-manager 的--horizontal-pod-autoscaler-sync-period 参数进行设置),查询指定的资源中的 Pod 资源使用率,并且与创建时设定的值和指标做对比,从而实现自动伸缩的功能。
2.Metrics Server
在 HPA 的第一个版本中,我们需要 Heapster(目前这个已经废弃了) 提供 CPU 和内存指标,在 HPA v2 过后就需要安装 Metrcis Server 了,Metrics Server 可以通过标准的 Kubernetes API 把监控数据暴露出来,有了 Metrics Server 之后,我们就完全可以通过标准的 Kubernetes API 来访问我们想要获取的监控数据了:
https://10.96.0.1/apis/metrics.k8s.io/v1beta1/namespaces/<namespace-name>/pods/<pod-name>
比如当我们访问上面的 API 的时候,我们就可以获取到该 Pod 的资源数据,**这些数据其实是来自于 kubelet 的 Summary API 采集而来的。**不过需要说明的是我们这里可以通过标准的 API 来获取资源监控数据,并不是因为 Metrics Server 就是 APIServer 的一部分,而是通过 Kubernetes 提供的 Aggregator(聚合器) 汇聚插件来实现的,是独立于 APIServer 之外运行的。
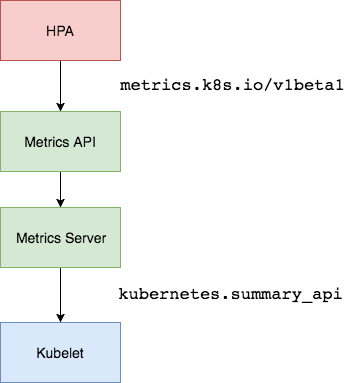
a.聚合 API
Aggregator 允许开发人员编写一个自己的服务,把这个服务注册到 Kubernetes 的 APIServer 里面去,这样我们就可以像原生的 APIServer 提供的 API 使用自己的 API 了,我们把自己的服务运行在 Kubernetes 集群里面,然后 Kubernetes 的 Aggregator 通过 Service 名称就可以转发到我们自己写的 Service 里面去了。这样这个聚合层就带来了很多好处:
- 增加了 API 的扩展性:开发人员可以编写自己的 API 服务来暴露他们想要的 API。
- 丰富了 API:核心 kubernetes 团队阻止了很多新的 API 提案,通过允许开发人员将他们的 API 作为单独的服务公开,这样就无须社区繁杂的审查了。
- 开发分阶段实验性 API:新的 API 可以在单独的聚合服务中开发,当它稳定之后,在合并会 APIServer 就很容易了。
- 确保新 API 遵循 Kubernetes 约定:如果没有这里提出的机制,社区成员可能会被迫推出自己的东西,这样很可能造成社区成员和社区约定不一致。
3.什么是vpa
hpa:水平自动扩缩容
vpa:垂直自动扩缩容,我始终在一个pod里面,假设我的memory limits是100Mi,但是现在已经用到了98Mi,如果再大的话就oom了,此时vpa会在垂直方向上提升你的memory limits的大小。这种vpa比较适合一些资源消耗比较大的应用,例如es,你给大了资源浪费,给小了,又不够。所以vpa就派上用场了。当然,vpa不像hpa默认集成在k8s里面的,需要你自己去配置的。
另外:vpa会涉及一些CRD的operator里的一些知识。
[root@master1 ~]#vim hpa-demo.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: hpa-demo
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
resources:
requests:
memory: 50Mi
cpu: 50m
limits:
memory: 100Mi
cpu: 100m
2、实战演示
实战演示1:安装metrics-server
安装前须知
需要开启Aggreator
所以现在我们要使用 HPA,就需要在集群中安装 Metrics Server 服务,要安装 Metrics Server 就需要开启 Aggregator,因为 Metrics Server 就是通过该代理进行扩展的,不过我们集群是通过 Kubeadm 搭建的,默认已经开启了,如果是二进制方式安装的集群,需要单独配置 kube-apsierver 添加如下所示的参数:
--requestheader-client-ca-file=<path to aggregator CA cert>
--requestheader-allowed-names=aggregator
--requestheader-extra-headers-prefix=X-Remote-Extra-
--requestheader-group-headers=X-Remote-Group
--requestheader-username-headers=X-Remote-User
--proxy-client-cert-file=<path to aggregator proxy cert>
--proxy-client-key-file=<path to aggregator proxy key>
这里我们可以看一下当时用kubeadm搭建的k8s集群的kube-apiserver.yaml文件:
[root@master1 ~]#cat /etc/kubernetes/manifests/kube-apiserver.yaml
……
- --proxy-client-cert-file=/etc/kubernetes/pki/front-proxy-client.crt
- --proxy-client-key-file=/etc/kubernetes/pki/front-proxy-client.key
- --requestheader-allowed-names=front-proxy-client
- --requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.crt
- --requestheader-extra-headers-prefix=X-Remote-Extra-
- --requestheader-group-headers=X-Remote-Group
- --requestheader-username-headers=X-Remote-User
……
如果 kube-proxy 没有和 APIServer 运行在同一台主机上,那么需要确保启用了如下 kube-apsierver 的参数:
--enable-aggregator-routing=true
对于这些证书的生成方式,我们可以查看官方文档:https://github.com/kubernetes-sigs/apiserver-builder-alpha/blob/master/docs/concepts/auth.md。
我们可以先来看看这个metrics server的gitbub地址:
https://github.com/kubernetes-sigs/metrics-server


step1:下载仓库官方metrics server安装的资源清单
Aggregator 聚合层启动完成后,就可以来安装 Metrics Server 了,我们可以获取该仓库的官方安装资源清单:
# 官方仓库地址:https://github.com/kubernetes-sigs/metrics-server
➜ ~ wget https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.5.1/components.yaml
[root@master1 ~]#wget https://download.fastgit.org/kubernetes-sigs/metrics-server/releases/download/v0.5.1/components.yaml
[root@master1 ~]#ll -h components.yaml
-rw-r--r-- 1 root root 4.1K Sep 26 17:37 components.yaml
[root@master1 ~]#
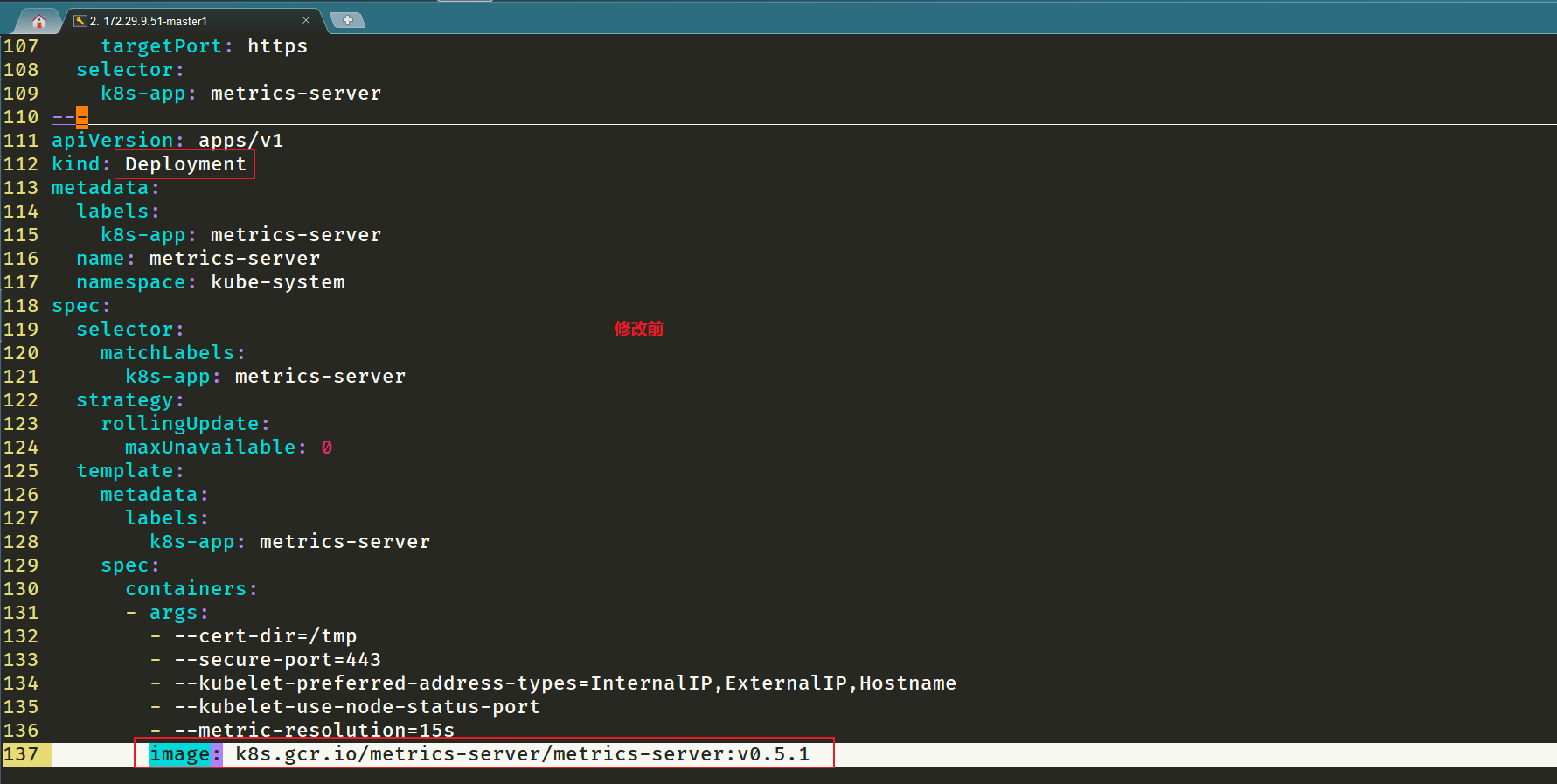
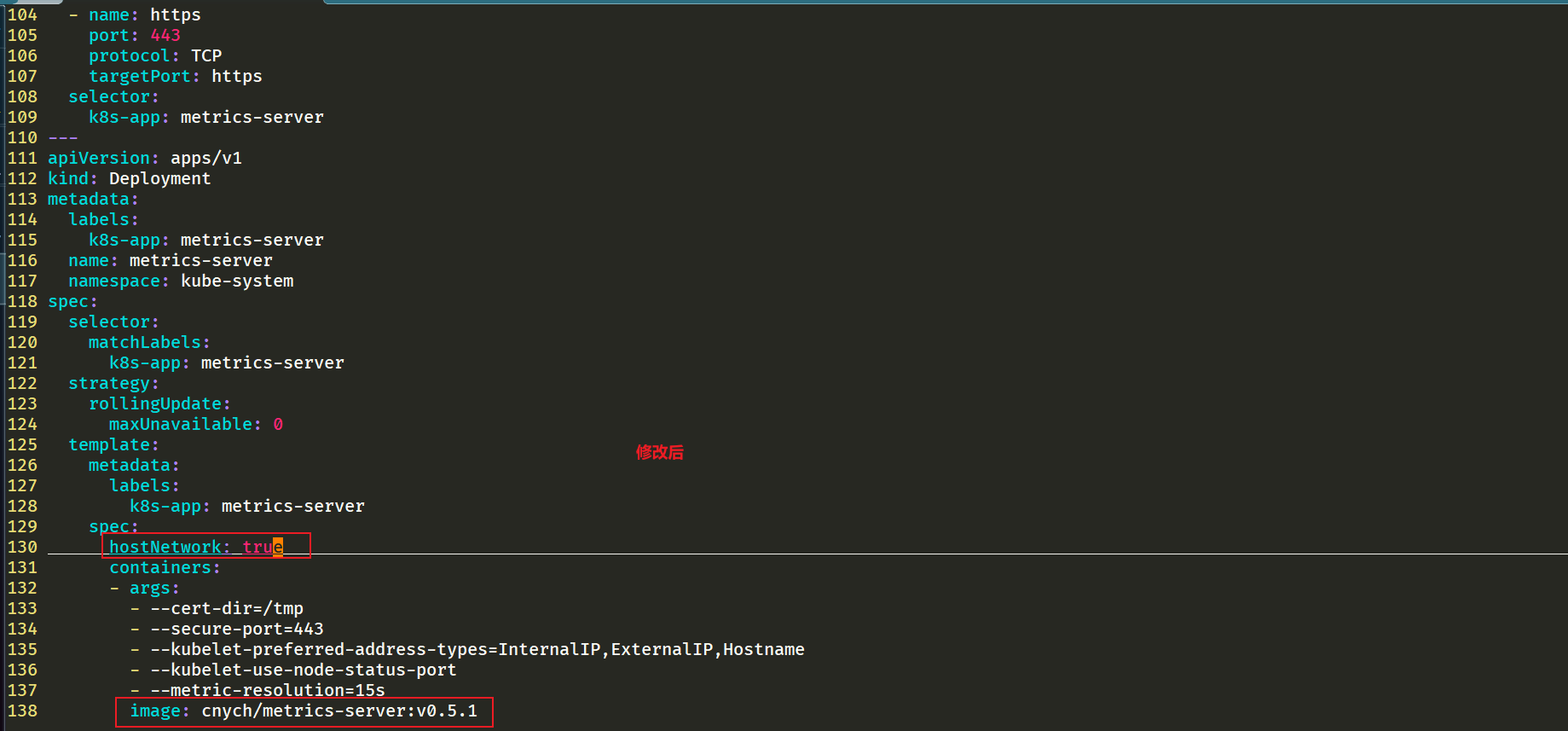
step2:修改 components.yaml 的镜像地址
在部署之前,修改 components.yaml 的镜像地址
#默认信息如下
[root@master1 ~]#vim components.yaml
……
137 image: k8s.gcr.io/metrics-server/metrics-server:v0.5.1
……
#修改为如下:
hostNetwork: true # #修改地方1 注意:使用hostNetwork模式
containers:
- name: metrics-server
image: cnych/metrics-server:v0.5.1 #修改地方2
step3:部署并查看pod日志
等部署完成后,可以查看 Pod 日志是否正常
[root@master1 ~]#kubectl apply -f components.yaml
serviceaccount/metrics-server created
clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created
clusterrole.rbac.authorization.k8s.io/system:metrics-server created
rolebinding.rbac.authorization.k8s.io/metrics-server-auth-reader created
clusterrolebinding.rbac.authorization.k8s.io/metrics-server:system:auth-delegator created
clusterrolebinding.rbac.authorization.k8s.io/system:metrics-server created
service/metrics-server created
deployment.apps/metrics-server created
apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created
[root@master1 ~]#kubectl get po -nkube-system -l k8s-app=metrics-server
NAME READY STATUS RESTARTS AGE
metrics-server-859bf7c488-gzgc2 0/1 Running 0 14s
[root@master1 ~]#kubectl logs -f metrics-server-859bf7c488-gzgc2 -nkube-system
I1121 14:02:02.659804 1 shared_informer.go:247] Caches are synced for RequestHeaderAuthRequestController
I1121 14:02:02.660030 1 shared_informer.go:247] Caches are synced for client-ca::kube-system::extension-apiserver-authentication::client-ca-file
E1121 14:02:17.483842 1 scraper.go:139] "Failed to scrape node" err="Get \"https://172.29.9.52:10250/stats/summary?only_cpu_and_memory=true\": x509: cannot validate certificate for 172.29.9.52 because it doesn't contain any IP SANs" node="node1"
E1121 14:02:17.488667 1 scraper.go:139] "Failed to scrape node" err="Get \"https://172.29.9.53:10250/stats/summary?only_cpu_and_memory=true\": x509: cannot validate certificate for 172.29.9.53 because it doesn't contain any IP SANs" node="node2"
E1121 14:02:17.491507 1 scraper.go:139] "Failed to scrape node" err="Get \"https://172.29.9.51:10250/stats/summary?only_cpu_and_memory=true\": x509: cannot validate certificate for 172.29.9.51 because it doesn't contain any IP SANs" node="master1"
I1121 14:02:26.729083 1 server.go:188] "Failed probe" probe="metric-storage-ready" err="not metrics to serve"
E1121 14:02:32.493248 1 scraper.go:139] "Failed to scrape node" err="Get \"https://172.29.9.52:10250/stats/summary?only_cpu_and_memory=true\": x509: cannot validate certificate for 172.29.9.52 because it doesn't contain any IP SANs" node="node1"
E1121 14:02:32.496511 1 scraper.go:139] "Failed to scrape node" err="Get \"https://172.29.9.53:10250/stats/summary?only_cpu_and_memory=true\": x509: cannot validate certificate for 172.29.9.53 because it doesn't contain any IP SANs" node="node2"
E1121 14:02:32.497923 1 scraper.go:139] "Failed to scrape node" err="Get \"https://172.29.9.51:10250/stats/summary?only_cpu_and_memory=true\": x509: cannot validate certificate for 172.29.9.51 because it doesn't contain any IP SANs" node="master1"
I1121 14:02:36.729694 1 server.go:188] "Failed probe" probe="metric-storage-ready" err="not metrics to serve"
I1121 14:02:46.724972 1 server.go:188] "Failed probe" probe="metric-storage-ready" err="not metrics to serve"
E1121 14:02:47.482222 1 scraper.go:139] "Failed to scrape node" err="Get \"https://172.29.9.53:10250/stats/summary?only_cpu_and_memory=true\": x509: cannot validate certificate for 172.29.9.53 because it doesn't contain any IP SANs" node="node2"
E1121 14:02:47.483545 1 scraper.go:139] "Failed to scrape node" err="Get \"https://172.29.9.52:10250/stats/summary?only_cpu_and_memory=true\": x509: cannot validate certificate for 172.29.9.52 because it doesn't contain any IP SANs" node="node1"
E1121 14:02:47.484900 1 scraper.go:139] "Failed to scrape node" err="Get \"https://172.29.9.51:10250/stats/summary?only_cpu_and_memory=true\": x509: cannot validate certificate for 172.29.9.51 because it doesn't contain any IP SANs" node="master1"
I1121 14:02:56.730788 1 server.go:188] "Failed probe" probe="metric-storage-ready" err="not metrics to serve"
E1121 14:03:02.474429 1 scraper.go:139] "Failed to scrape node" err="Get \"https://172.29.9.52:10250/stats/summary?only_cpu_and_memory=true\": x509: cannot validate certificate for 172.29.9.52 because it doesn't contain any IP SANs" node="node1"
E1121 14:03:02.481516 1 scraper.go:139] "Failed to scrape node" err="Get \"https://172.29.9.51:10250/stats/summary?only_cpu_and_memory=true\": x509: cannot validate certificate for 172.29.9.51 because it doesn't contain any IP SANs" node="master1"
E1121 14:03:02.495061 1 scraper.go:139] "Failed to scrape node" err="Get \"https://172.29.9.53:10250/stats/summary?only_cpu_and_memory=true\": x509: cannot validate certificate for 172.29.9.53 because it doesn't contain any IP SANs" node="node2"
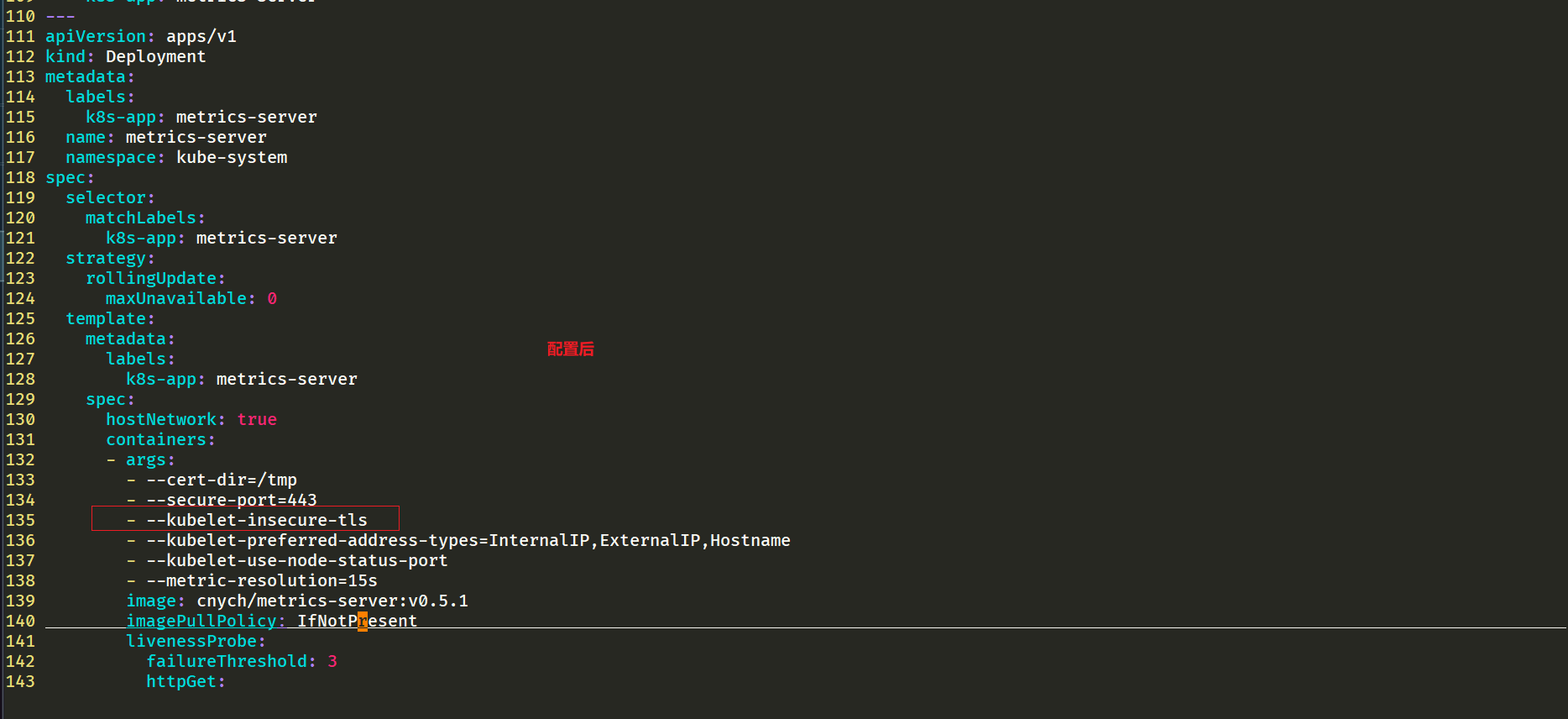
step4:添加一个--kubelet-insecure-tls参数跳过证书校验
因为部署集群的时候,CA 证书并没有把各个节点的 IP 签上去,所以这里 Metrics Server 通过 IP 去请求时,提示签的证书没有对应的 IP(错误:x509: cannot validate certificate for 172.29.9.52 because it doesn't contain any IP SANs),我们可以添加一个--kubelet-insecure-tls参数跳过证书校验:
个人对这里的知识点有些模糊。。。
[root@master1 ~]#vim components.yaml
args:
- --cert-dir=/tmp
- --secure-port=4443
- --kubelet-insecure-tls #修改1:
- --kubelet-preferred-address-types=InternalIP
step5:再次部署并查看
然后再重新安装即可成功!可以通过如下命令来验证:
[root@master1 ~]#kubectl apply -f components.yaml
serviceaccount/metrics-server unchanged
clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader unchanged
clusterrole.rbac.authorization.k8s.io/system:metrics-server unchanged
rolebinding.rbac.authorization.k8s.io/metrics-server-auth-reader unchanged
clusterrolebinding.rbac.authorization.k8s.io/metrics-server:system:auth-delegator unchanged
clusterrolebinding.rbac.authorization.k8s.io/system:metrics-server unchanged
service/metrics-server unchanged
deployment.apps/metrics-server configured
apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io unchanged
[root@master1 ~]#kubectl get po -nkube-system -l k8s-app=metrics-server
NAME READY STATUS RESTARTS AGE
metrics-server-76b8bfbb47-8v2lr 1/1 Running 0 68s
[root@master1 ~]#kubectl logs -f metrics-server-76b8bfbb47-8v2lr -nkube-system
I1121 14:14:21.820418 1 serving.go:341] Generated self-signed cert (/tmp/apiserver.crt, /tmp/apiserver.key)
I1121 14:14:22.641351 1 requestheader_controller.go:169] Starting RequestHeaderAuthRequestController
I1121 14:14:22.641382 1 shared_informer.go:240] Waiting for caches to sync for RequestHeaderAuthRequestController
I1121 14:14:22.641418 1 configmap_cafile_content.go:202] Starting client-ca::kube-system::extension-apiserver-authentication::client-ca-file
I1121 14:14:22.641427 1 shared_informer.go:240] Waiting for caches to sync for client-ca::kube-system::extension-apiserver-authentication::client-ca-file
I1121 14:14:22.641444 1 configmap_cafile_content.go:202] Starting client-ca::kube-system::extension-apiserver-authentication::requestheader-client-ca-file
I1121 14:14:22.641480 1 shared_informer.go:240] Waiting for caches to sync for client-ca::kube-system::extension-apiserver-authentication::requestheader-client-ca-file
I1121 14:14:22.641800 1 secure_serving.go:202] Serving securely on [::]:443
I1121 14:14:22.641923 1 dynamic_serving_content.go:130] Starting serving-cert::/tmp/apiserver.crt::/tmp/apiserver.key
I1121 14:14:22.641952 1 tlsconfig.go:240] Starting DynamicServingCertificateController
I1121 14:14:22.743183 1 shared_informer.go:247] Caches are synced for client-ca::kube-system::extension-apiserver-authentication::requestheader-client-ca-file
I1121 14:14:22.743195 1 shared_informer.go:247] Caches are synced for client-ca::kube-system::extension-apiserver-authentication::client-ca-file
I1121 14:14:22.743300 1 shared_informer.go:247] Caches are synced for RequestHeaderAuthRequestController
[root@master1 ~]#kubectl get apiservices.apiregistration.k8s.io #我们来看一下api service服务
NAME SERVICE AVAILABLE AGE
v1. Local True 21d
v1.admissionregistration.k8s.io Local True 21d
v1.apiextensions.k8s.io Local True 21d
v1.apps Local True 21d
v1.authentication.k8s.io Local True 21d
v1.authorization.k8s.io Local True 21d
v1.autoscaling Local True 21d
v1.batch Local True 21d
v1.certificates.k8s.io Local True 21d
v1.coordination.k8s.io Local True 21d
v1.discovery.k8s.io Local True 21d
v1.events.k8s.io Local True 21d
v1.networking.k8s.io Local True 21d
v1.node.k8s.io Local True 21d
v1.policy Local True 21d
v1.rbac.authorization.k8s.io Local True 21d
v1.scheduling.k8s.io Local True 21d
v1.storage.k8s.io Local True 21d
v1beta1.batch Local True 21d
v1beta1.discovery.k8s.io Local True 21d
v1beta1.events.k8s.io Local True 21d
v1beta1.flowcontrol.apiserver.k8s.io Local True 21d
v1beta1.metrics.k8s.io kube-system/metrics-server True 18m
v1beta1.node.k8s.io Local True 21d
v1beta1.policy Local True 21d
v1beta1.storage.k8s.io Local True 21d
v2beta1.autoscaling Local True 21d
v2beta2.autoscaling Local True 21d
[root@master1 ~]#kubectl get --raw "/apis/metrics.k8s.io/v1beta1/nodes"
{
"kind":"NodeMetricsList","apiVersion":"metrics.k8s.io/v1beta1","metadata":{
},"items":[{
"metadata":{
"name":"master1","creationTimestamp":"2021-11-21T14:22:54Z","labels":{
"beta.kubernetes.io/arch":"amd64","beta.kubernetes.io/os":"linux","kubernetes.io/arch":"amd64","kubernetes.io/hostname":"master1","kubernetes.io/os":"linux","node-role.kubernetes.io/control-plane":"","node-role.kubernetes.io/master":"","node.kubernetes.io/exclude-from-external-load-balancers":""}},"timestamp":"2021-11-21T14:22:48Z","window":"20s","usage":{
"cpu":"223908852n","memory":"1115576Ki"}},{
"metadata":{
"name":"node1","creationTimestamp":"2021-11-21T14:22:54Z","labels":{
"beta.kubernetes.io/arch":"amd64","beta.kubernetes.io/os":"linux","kubernetes.io/arch":"amd64","kubernetes.io/hostname":"node1","kubernetes.io/os":"linux"}},"timestamp":"2021-11-21T14:22:44Z","window":"10s","usage":{
"cpu":"55788161n","memory":"934188Ki"}},{
"metadata":{
"name":"node2","creationTimestamp":"2021-11-21T14:22:54Z","labels":{
"beta.kubernetes.io/arch":"amd64","beta.kubernetes.io/os":"linux","kubernetes.io/arch":"amd64","kubernetes.io/hostname":"node2","kubernetes.io/os":"linux"}},"timestamp":"2021-11-21T14:22:47Z","window":"10s","usage":{
"cpu":"1030374296n","memory":"877584Ki"}}]}
[root@master1 ~]#
step6:验证效果
现在我们可以通过 kubectl top 命令来获取到资源数据了,证明 Metrics Server 已经安装成功了。
[root@master1 ~]#kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
master1 223m 11% 1090Mi 63%
node1 58m 2% 911Mi 53%
node2 1031m 51% 859Mi 49%
[root@master1 ~]#kubectl top po -nkube-system
NAME CPU(cores) MEMORY(bytes)
coredns-7568f67dbd-9dls5 2m 26Mi
coredns-7568f67dbd-kqhjq 2m 17Mi
etcd-master1 25m 125Mi
kube-apiserver-master1 109m 311Mi
kube-controller-manager-master1 30m 77Mi
kube-flannel-ds-5lm5t 3m 15Mi
kube-flannel-ds-rmtfk 3m 17Mi
kube-flannel-ds-xbp6g 3m 16Mi
kube-proxy-4sw76 12m 31Mi
kube-proxy-mkghd 1m 21Mi
kube-proxy-s2748 6m 20Mi
kube-scheduler-master1 4m 35Mi
metrics-server-76b8bfbb47-8v2lr 5m 15Mi
[root@master1 ~]#
现在一切准备就绪,接下来我们就可以来测试HPA了。
实战演示2:测试HPA(默认是CPU的hpa)
step1:创建一个Nginx pod资源清单文件
现在我们用 Deployment 来创建一个 Nginx Pod,然后利用 HPA 来进行自动扩缩容。资源清单如下所示:
[root@master1 ~]#vim hpa-demo.yaml
# hpa-demo.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: hpa-demo
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
step2: 部署并查看
然后直接创建 Deployment,注意一定先把之前创建的具有 app=nginx 的 Pod 先清除掉:
[root@master1 ~]#kubectl apply -f hpa-demo.yaml
deployment.apps/hpa-demo created
[root@master1 ~]#kubectl get po
NAME READY STATUS RESTARTS AGE
hpa-demo-7848d4b86f-fdfxw 1/1 Running 0 39s
step3: 创建一个 HPA 资源对象
现在我们来创建一个 HPA 资源对象,可以使用kubectl autoscale命令来创建:(我们也可以先用kubectl explains hpa.spec来查看下hpa资源的可用字段:)
[root@master1 ~]#kubectl autoscale deployment hpa-demo --cpu-percent=10 --min=1 --max=10
horizontalpodautoscaler.autoscaling/hpa-demo autoscaled
[root@master1 ~]#kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa-demo Deployment/hpa-demo <unknown>/10% 1 10 0 12s
#注意:这里的`unkown`字段和`replicas`字段,都是异常的;
此命令创建了一个关联资源 hpa-demo 的 HPA,最小的 Pod 副本数为1,最大为10。HPA 会根据设定的 cpu 使用率(10%)动态的增加或者减少 Pod 数量。
当然我们依然还是可以通过创建 YAML 文件的形式来创建 HPA 资源对象。如果我们不知道怎么编写的话,可以查看上面命令行创建的HPA的YAML文件:
[root@master1 ~]#kubectl get hpa -oyaml
apiVersion: v1
items:
- apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
annotations:
autoscaling.alpha.kubernetes.io/conditions: '[{
"type":"AbleToScale","status":"True","lastTransitionTime":"2021-11-22T11:12:12Z","reason":"SucceededGetScale","message":"the
HPA controller was able to get the target''s current scale"},{
"type":"ScalingActive","status":"False","lastTransitionTime":"2021-11-22T11:12:12Z","reason":"FailedGetResourceMetric","message":"the
HPA was unable to compute the replica count: failed to get cpu utilization:
missing request for cpu"}]'
creationTimestamp: "2021-11-22T11:11:57Z"
name: hpa-demo
namespace: default
resourceVersion: "507353"
uid: df884caa-e07d-49b0-ab95-6f67c05e522b
spec:
maxReplicas: 10
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: hpa-demo
targetCPUUtilizationPercentage: 10
status:
currentReplicas: 1
desiredReplicas: 0
kind: List
metadata:
resourceVersion: ""
selfLink: ""
[root@master1 ~]#
step4:发现一些fail信息并排查
然后我们可以根据上面的 YAML 文件就可以自己来创建一个基于 YAML 的 HPA 描述文件了。但是我们发现上面信息里面出现了一些 Fail 信息,我们来查看下这个 HPA 对象的信息:
[root@master1 ~]#kubectl describe hpa hpa-demo
Name: hpa-demo
Namespace: default
Labels: <none>
Annotations: <none>
CreationTimestamp: Mon, 22 Nov 2021 19:11:57 +0800
Reference: Deployment/hpa-demo
Metrics: ( current / target )
resource cpu on pods (as a percentage of request): <unknown> / 10%
Min replicas: 1
Max replicas: 10
Deployment pods: 1 current / 0 desired
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True SucceededGetScale the HPA controller was able to get the target's current scale
ScalingActive False FailedGetResourceMetric the HPA was unable to compute the replica count: failed to get cpu utilization: missing request for cpu
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedComputeMetricsReplicas 19s (x12 over 3m4s) horizontal-pod-autoscaler invalid metrics (1 invalid out of 1), first error is: failed to get cpu utilization: missing request for cpu
Warning FailedGetResourceMetric 4s (x13 over 3m4s) horizontal-pod-autoscaler failed to get cpu utilization: missing request for cpu
我们可以看到上面的事件信息里面出现了 failed to get cpu utilization: missing request for cpu 这样的错误信息。这是因为我们上面创建的 Pod 对象没有添加 request 资源声明,这样导致 HPA 读取不到 CPU 指标信息,所以如果要想让 HPA 生效,对应的 Pod 资源必须添加 requests 资源声明,来更新我们的资源清单文件。
step5:资源清单文件里添加requests资源重新部署并查看
更新我们的资源清单文件,添加requests资源
[root@master1 ~]#vim hpa-demo.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: hpa-demo
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
resources:
requests:
memory: 50Mi
cpu: 50m
然后重新更新 Deployment,重新创建 HPA 对象:
[root@master1 ~]#kubectl apply -f hpa-demo.yaml
deployment.apps/hpa-demo configured
[root@master1 ~]#kubectl get po -l app=nginx -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
hpa-demo-6b4467b546-88rtv 1/1 Running 0 8m21s 10.244.2.154 node2 <none> <none>
[root@master1 ~]#
[root@master1 ~]#kubectl delete hpa hpa-demo
horizontalpodautoscaler.autoscaling "hpa-demo" deleted
[root@master1 ~]#kubectl autoscale deployment hpa-demo --cpu-percent=10 --min=1 --max=10
horizontalpodautoscaler.autoscaling/hpa-demo autoscaled
[root@master1 ~]#kubectl get hpa #当然现在这个pod的资源使用率不可能是0%
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa-demo Deployment/hpa-demo 0%/10% 1 10 1 30s
[root@master1 ~]#kubectl describe hpa hpa-demo
Name: hpa-demo
Namespace: default
Labels: <none>
Annotations: <none>
CreationTimestamp: Mon, 22 Nov 2021 19:29:16 +0800
Reference: Deployment/hpa-demo
Metrics: ( current / target )
resource cpu on pods (as a percentage of request): 0% (0) / 10%
Min replicas: 1
Max replicas: 10
Deployment pods: 1 current / 1 desired
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True ScaleDownStabilized recent recommendations were higher than current one, applying the highest recent recommendation
ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from cpu resource utilization (percentage of request)
ScalingLimited False DesiredWithinRange the desired count is within the acceptable range
Events: <none>
[root@master1 ~]#
现在可以看到 HPA 资源对象已经正常了。
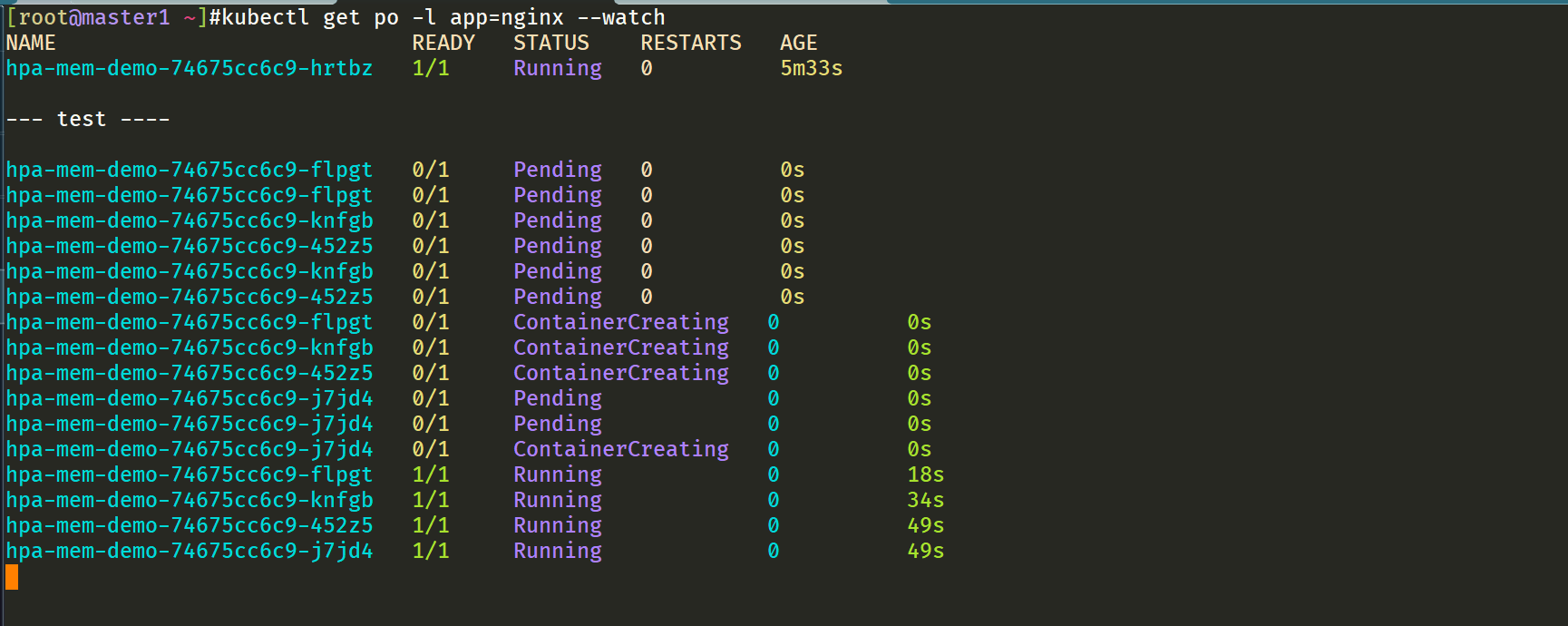
step6:我们来创建一个pod模拟增大负载进行测试
now,我们来增大负载进行测试,我们来创建一个 busybox 的 Pod,并且循环访问上面创建的 Pod:
我们新打开一个终端:
root@master1 ~]#kubectl run -it --image busybox test-hpa --restart=Never --rm /bin/sh
If you don't see a command prompt, try pressing enter.
/ # while true; do wget -q -O- http://10.244.2.154; done
然后观察 Pod 列表,可以看到,HPA 已经开始工作:
[root@master1 ~]#kubectl get hpa --watch
[root@master1 ~]#kubectl get po -l app=nginx --watch
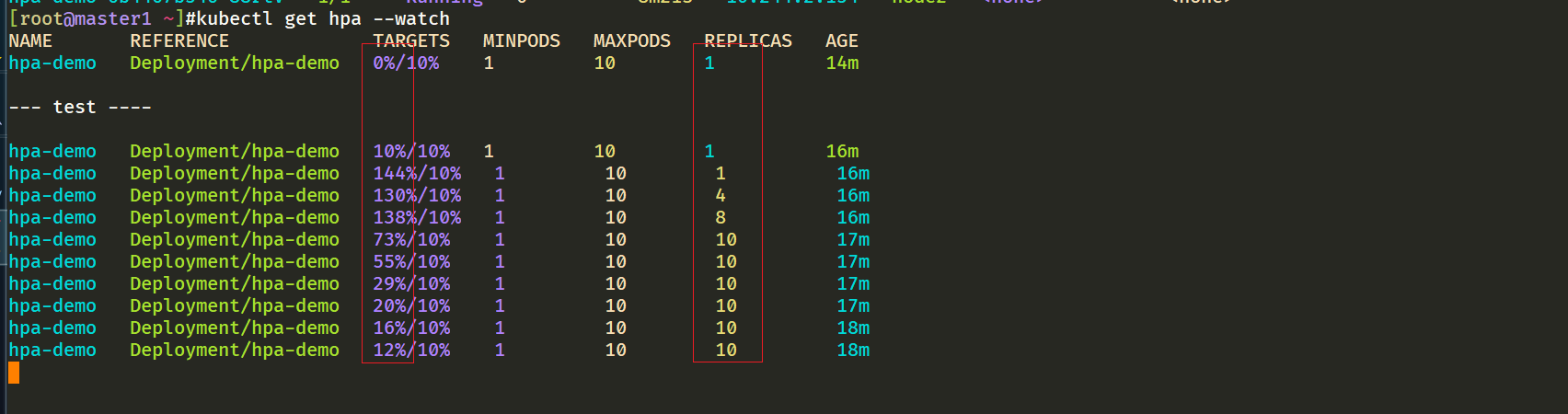
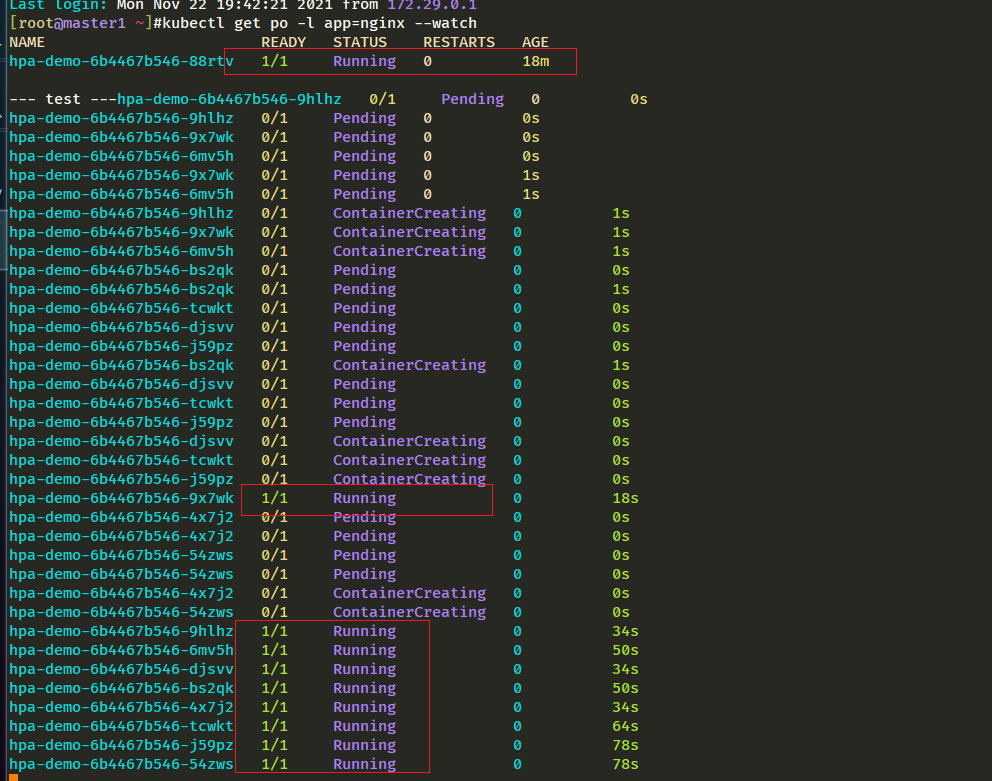
我们可以看到已经自动拉起了很多新的 Pod,最后会定格在了我们上面设置的 10 个 Pod,同时查看资源 hpa-demo 的副本数量,副本数量已经从原来的1变成了10个:
[root@master1 ~]#kubectl get deployments.apps hpa-demo
NAME READY UP-TO-DATE AVAILABLE AGE
hpa-demo 10/10 10 10 49m
[root@master1 ~]#
查看 HPA 资源的对象了解工作过程:
[root@master1 ~]#kubectl describe hpa hpa-demo
Name: hpa-demo
Namespace: default
Labels: <none>
Annotations: <none>
CreationTimestamp: Mon, 22 Nov 2021 19:29:16 +0800
Reference: Deployment/hpa-demo
Metrics: ( current / target )
resource cpu on pods (as a percentage of request): 15% (7m) / 10%
Min replicas: 1
Max replicas: 10
Deployment pods: 10 current / 10 desired
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True ScaleDownStabilized recent recommendations were higher than current one, applying the highest recent recommendation
ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from cpu resource utilization (percentage of request)
ScalingLimited True TooManyReplicas the desired replica count is more than the maximum replica count
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulRescale 4m20s horizontal-pod-autoscaler New size: 4; reason: cpu resource utilization (percentage of request) above target
Normal SuccessfulRescale 4m5s horizontal-pod-autoscaler New size: 8; reason: cpu resource utilization (percentage of request) above target
Normal SuccessfulRescale 3m49s horizontal-pod-autoscaler New size: 10; reason: cpu resource utilization (percentage of request) above target
[root@master1 ~]#
step7: 我们来关掉 busybox 来减少负载
同样的这个时候我们来关掉 busybox 来减少负载,然后等待一段时间观察下 HPA 和 Deployment 对象:
[root@master1 ~]#kubectl get hpa --watch
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa-demo Deployment/hpa-demo 16%/10% 1 10 10 21m
hpa-demo Deployment/hpa-demo 12%/10% 1 10 10 21m
hpa-demo Deployment/hpa-demo 0%/10% 1 10 10 21m
[root@master1 ~]#kubectl get po
NAME READY STATUS RESTARTS AGE
hpa-demo-6b4467b546-4x7j2 1/1 Running 0 5m25s
hpa-demo-6b4467b546-54zws 1/1 Running 0 5m25s
hpa-demo-6b4467b546-6mv5h 1/1 Running 0 5m56s
hpa-demo-6b4467b546-88rtv 1/1 Running 0 26m
hpa-demo-6b4467b546-9hlhz 1/1 Running 0 5m56s
hpa-demo-6b4467b546-9x7wk 1/1 Running 0 5m56s
hpa-demo-6b4467b546-bs2qk 1/1 Running 0 5m41s
hpa-demo-6b4467b546-djsvv 1/1 Running 0 5m40s
hpa-demo-6b4467b546-j59pz 1/1 Running 0 5m40s
hpa-demo-6b4467b546-tcwkt 1/1 Running 0 5m40s
[root@master1 ~]#kubectl get deployments.apps hpa-demo
NAME READY UP-TO-DATE AVAILABLE AGE
hpa-demo 10/10 10 10 51m
[root@master1 ~]#
缩放间隙:
从 Kubernetesv1.12版本开始我们可以通过设置kube-controller-manager组件的--horizontal-pod-autoscaler-downscale-stabilization参数来设置一个持续时间,用于指定在当前操作完成后,HPA必须等待多长时间才能执行另一次缩放操作。默认为5分钟,也就是默认需要等待5分钟后才会开始自动缩放。
可以看到副本数量已经由 10 变为 1,当前我们只是演示了 CPU 使用率这一个指标,在后面的课程中我们还会学习到根据自定义的监控指标来自动对 Pod 进行扩缩容。
实验结束。
实战演示3:测试HPA(内存的hpa)
注意:在做本次实验前,把上一个实验的all资源全部卸载掉,以方便精确测试实验。
step1: 创建资源清单文件
要使用基于内存或者自定义指标进行扩缩容(现在的版本都必须依赖 metrics-server 这个项目)。现在我们再用 Deployment 来创建一个 Nginx Pod,然后利用 HPA 来进行自动扩缩容。资源清单如下所示:
# hpa-mem-demo.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: hpa-mem-demo
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
volumes:
- name: increase-mem-script
configMap:
name: increase-mem-config
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
volumeMounts:
- name: increase-mem-script
mountPath: /etc/script
resources:
requests:
memory: 50Mi
cpu: 50m
securityContext:
privileged: true
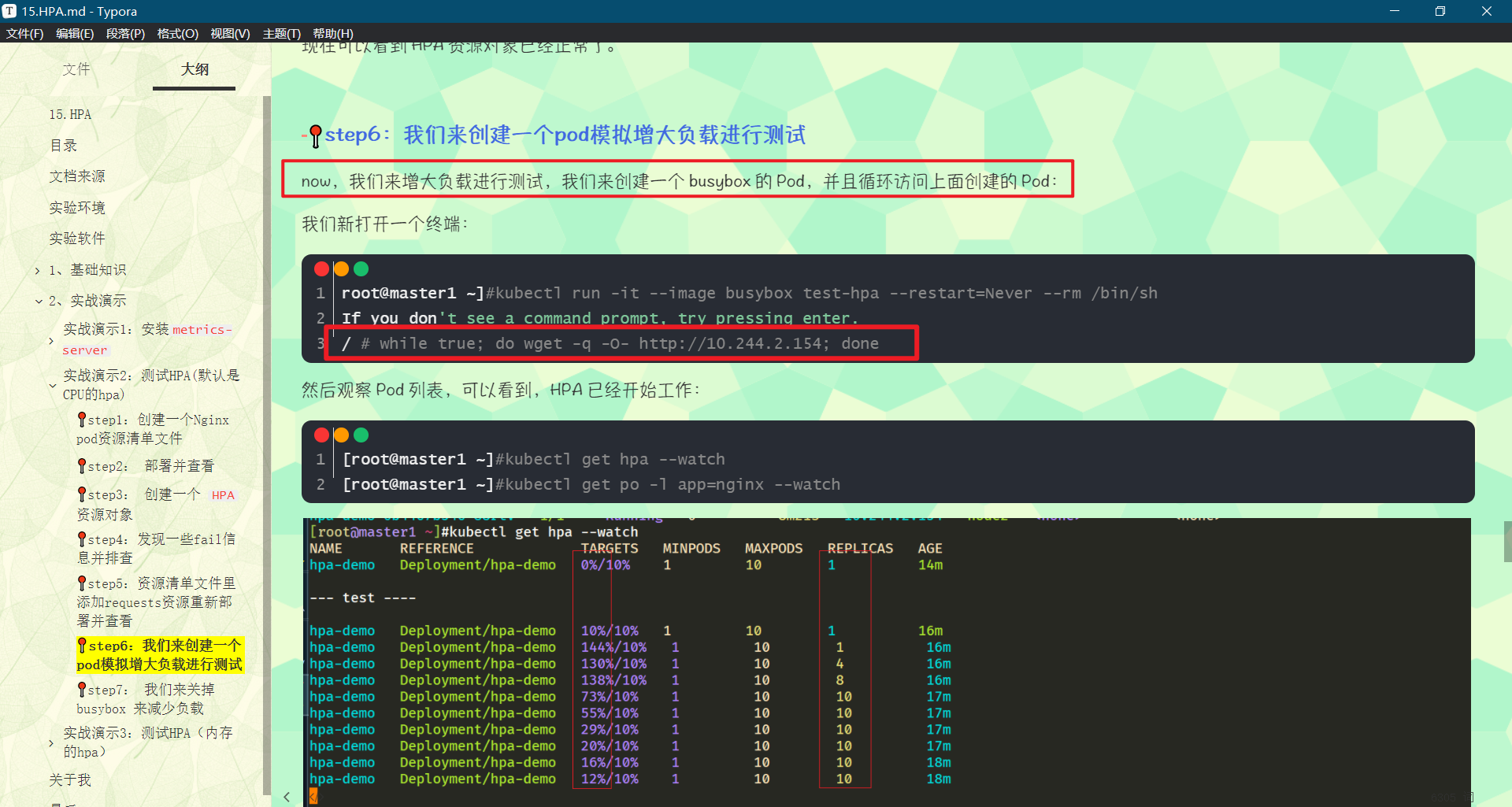
这里和前面普通的应用有一些区别,我们将一个名为 increase-mem-config 的 ConfigMap 资源对象挂载到了容器中,该配置文件是用于后面增加容器内存占用的脚本,配置文件如下所示:
# increase-mem-cm.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: increase-mem-config
data:
increase-mem.sh: |
#!/bin/bash
mkdir /tmp/memory
mount -t tmpfs -o size=40M tmpfs /tmp/memory
dd if=/dev/zero of=/tmp/memory/block
sleep 60
rm /tmp/memory/block
umount /tmp/memory
rmdir /tmp/memory
由于这里增加内存的脚本需要使用到 mount 命令,这需要声明为特权模式,所以我们添加了 securityContext.privileged=true 这个配置。
step2: 直接部署
现在我们直接创建上面的资源对象即可:
[root@master1 ~]#kubectl apply -f hpa-mem-demo.yaml
deployment.apps/hpa-mem-demo created
[root@master1 ~]#kubectl apply -f increase-mem-cm.yaml
configmap/increase-mem-config created
[root@master1 ~]#kubectl get po -l app=nginx
NAME READY STATUS RESTARTS AGE
hpa-mem-demo-74675cc6c9-hrtbz 1/1 Running 0 28s
step3:创建一个基于内存的 HPA 资源对象
然后需要创建一个基于内存的 HPA 资源对象:
[root@master1 ~]#vim hpa-mem.yaml
# hpa-mem.yaml
apiVersion: autoscaling/v2beta1 #注意:这里是v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: hpa-mem-demo
namespace: default
spec:
maxReplicas: 5
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: hpa-mem-demo
metrics: # 指定内存的一个配置
- type: Resource
resource:
name: memory
targetAverageUtilization: 20
要注意这里使用的 apiVersion 是 autoscaling/v2beta1,然后 metrics 属性里面指定的是内存的配置。
注意:扩容目标引用(scaleTargetRef ):
扩容目标引用(scaleTargetRef ):后面可以是一个deployment或者是replicaset。
一个hpa和一个例如deployment是一一对应的。
step4:直接创建上面的资源对象即可
[root@master1 ~]#kubectl apply -f hpa-mem.yaml
Warning: autoscaling/v2beta1 HorizontalPodAutoscaler is deprecated in v1.22+, unavailable in v1.25+; use autoscaling/v2beta2 HorizontalPodAutoscaler
horizontalpodautoscaler.autoscaling/hpa-mem-demo created
[root@master1 ~]#kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa-mem-demo Deployment/hpa-mem-demo 3%/20% 1 5 1 39s
[root@master1 ~]#
到这里证明 HPA 资源对象已经部署成功了。
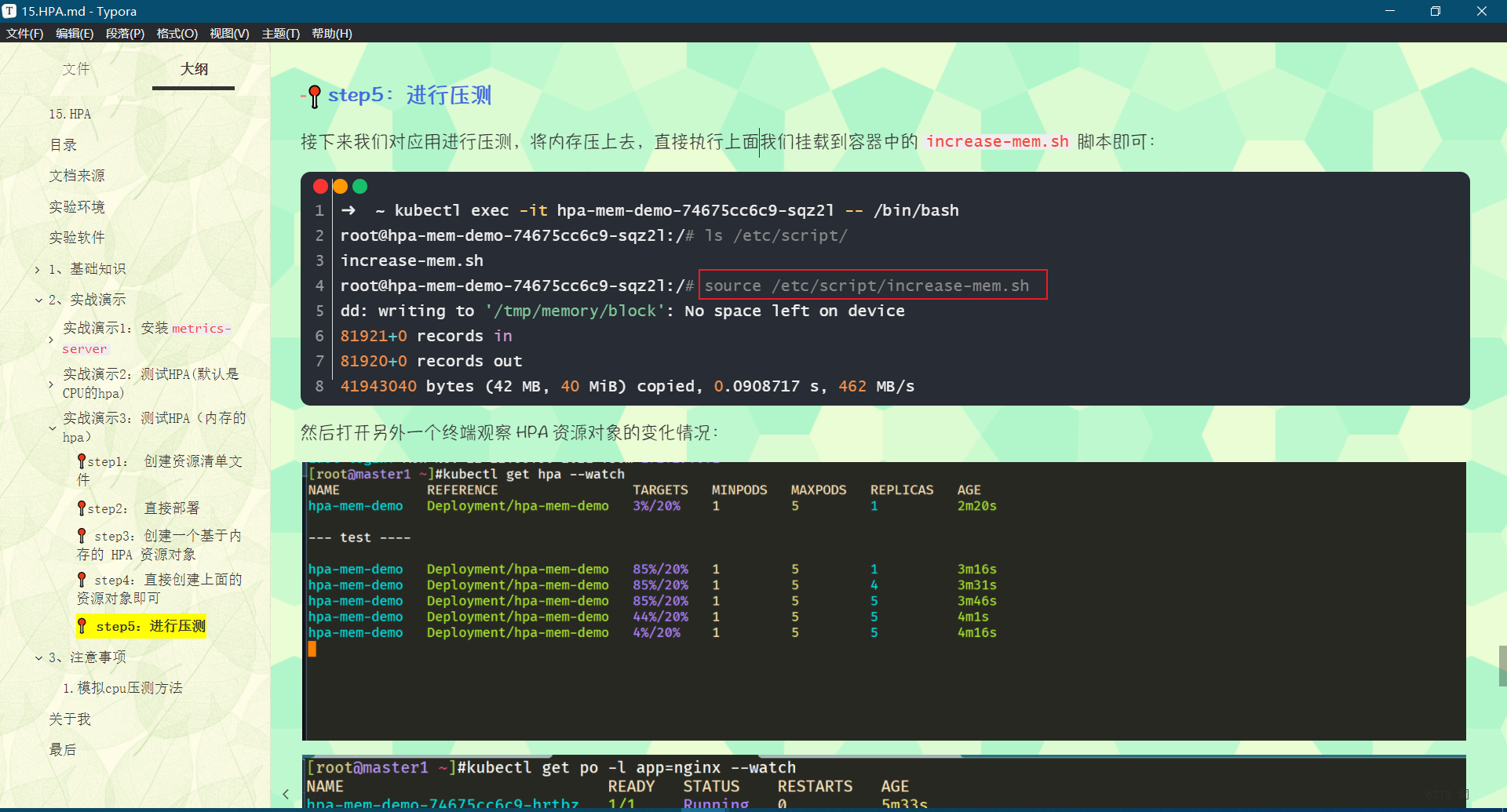
step5:进行压测
接下来我们对应用进行压测,将内存压上去,直接执行上面我们挂载到容器中的 increase-mem.sh 脚本即可:
➜ ~ kubectl exec -it hpa-mem-demo-74675cc6c9-sqz2l -- /bin/bash
root@hpa-mem-demo-74675cc6c9-sqz2l:/# ls /etc/script/
increase-mem.sh
root@hpa-mem-demo-74675cc6c9-sqz2l:/# source /etc/script/increase-mem.sh
dd: writing to '/tmp/memory/block': No space left on device
81921+0 records in
81920+0 records out
41943040 bytes (42 MB, 40 MiB) copied, 0.0908717 s, 462 MB/s
然后打开另外一个终端观察 HPA 资源对象的变化情况:
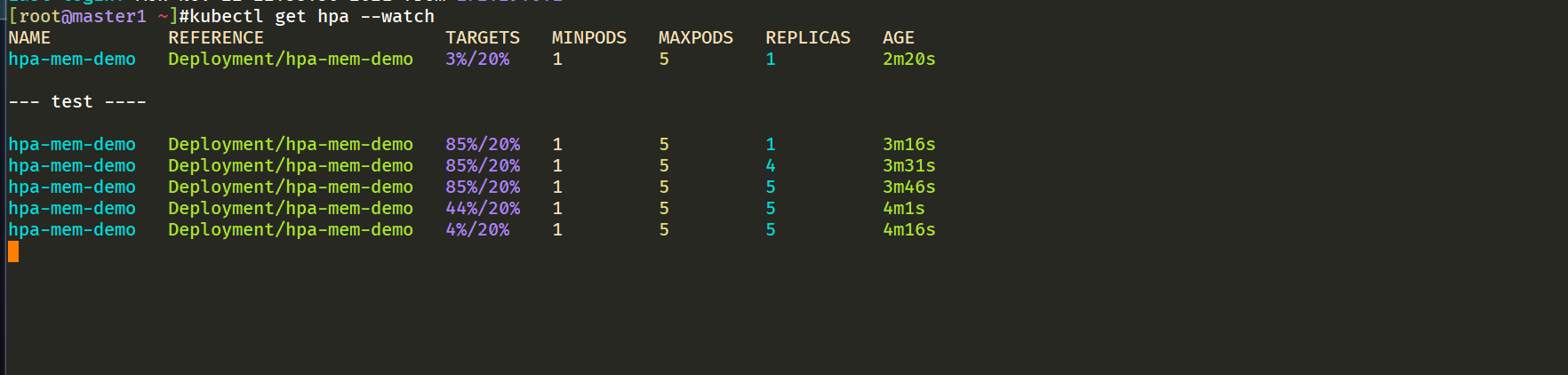
➜ ~ kubectl get hpa -w
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa-mem-demo Deployment/hpa-mem-demo 87%/30% 1 5 3 90s
➜ ~ kubectl describe hpa hpa-mem-demo
Name: hpa-mem-demo
Namespace: default
Labels: <none>
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{
"apiVersion":"autoscaling/v2beta1","kind":"HorizontalPodAutoscaler","metadata":{
"annotations":{
},"name":"hpa-mem-demo","namespace":"defau...
CreationTimestamp: Mon, 15 Nov 2021 18:40:37 +0800
Reference: Deployment/hpa-mem-demo
Metrics: ( current / target )
resource memory on pods (as a percentage of request): 87% (45752320) / 30%
Min replicas: 1
Max replicas: 5
Deployment pods: 3 current / 3 desired
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True ReadyForNewScale recommended size matches current size
ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from memory resource utilization (percentage of request)
ScalingLimited False DesiredWithinRange the desired count is within the acceptable range
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedGetResourceMetric 87s horizontal-pod-autoscaler failed to get memory utilization: unable to get metrics for resource memory: no metrics returned from resource metrics API
Warning FailedComputeMetricsReplicas 87s horizontal-pod-autoscaler invalid metrics (1 invalid out of 1), first error is: failed to get memory utilization: unable to get metrics for resource memory: no metrics returned from resource metrics API
Normal SuccessfulRescale 27s horizontal-pod-autoscaler New size: 3; reason: memory resource utilization (percentage of request) above target
Normal SuccessfulRescale 46s horizontal-pod-autoscaler New size: 4; reason: memory resource utilization (percentage of request) above target
➜ ~ kubectl top pod hpa-mem-demo-74675cc6c9-gbj9t
NAME CPU(cores) MEMORY(bytes)
hpa-mem-demo-66944b79bf-tqrn9 0m 41Mi
可以看到内存使用已经超过了我们设定的 30% 这个阈值了,HPA 资源对象也已经触发了自动扩容,变成了4个副本了:
➜ ~ kubectl get pods -l app=nginx
NAME READY STATUS RESTARTS AGE
hpa-mem-demo-74675cc6c9-cpdw4 1/1 Running 0 69s
hpa-mem-demo-74675cc6c9-s8bz4 1/1 Running 0 114s
hpa-mem-demo-74675cc6c9-sqz2l 1/1 Running 0 3m9s
hpa-mem-demo-74675cc6c9-z8cx8 1/1 Running 0 114s
当内存释放掉后,controller-manager 默认5分钟过后会进行缩放,到这里就完成了基于内存的 HPA 操作。
实验结束。
3、注意事项
1.cpu压测方法
root@master1 ~]#kubectl run -it --image busybox test-hpa --restart=Never --rm /bin/sh
If you don't see a command prompt, try pressing enter.
/ # while true; do wget -q -O- http://10.244.2.154; done
2.内存压测方法
3.ConfigMap的写法
要使用基于内存或者自定义指标进行扩缩容(现在的版本都必须依赖 metrics-server 这个项目)。现在我们再用 Deployment 来创建一个 Nginx Pod,然后利用 HPA 来进行自动扩缩容。资源清单如下所示:
# hpa-mem-demo.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: hpa-mem-demo
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
volumes:
- name: increase-mem-script
configMap:
name: increase-mem-config
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
volumeMounts:
- name: increase-mem-script
mountPath: /etc/script
resources:
requests:
memory: 50Mi
cpu: 50m
securityContext:
privileged: true
这里和前面普通的应用有一些区别,我们将一个名为 increase-mem-config 的 ConfigMap 资源对象挂载到了容器中,该配置文件是用于后面增加容器内存占用的脚本,配置文件如下所示:
# increase-mem-cm.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: increase-mem-config
data:
increase-mem.sh: |
#!/bin/bash
mkdir /tmp/memory
mount -t tmpfs -o size=40M tmpfs /tmp/memory
dd if=/dev/zero of=/tmp/memory/block
sleep 60
rm /tmp/memory/block
umount /tmp/memory
rmdir /tmp/memory
由于这里增加内存的脚本需要使用到 mount 命令,这需要声明为特权模式,所以我们添加了 securityContext.privileged=true 这个配置。
关于我
我的博客主旨:我希望每一个人拿着我的博客都可以做出实验现象,先把实验做出来,然后再结合理论知识更深层次去理解技术点,这样学习起来才有乐趣和动力。并且,我的博客内容步骤是很完整的,也分享源码和实验用到的软件,希望能和大家一起共同进步!
各位小伙伴在实际操作过程中如有什么疑问,可随时联系本人免费帮您解决问题:
-
个人微信二维码:x2675263825 (舍得), qq:2675263825。

-
个人博客地址:www.onlyonexl.cn
-
个人微信公众号:云原生架构师实战

-
个人csdn
https://blog.csdn.net/weixin_39246554?spm=1010.2135.3001.5421
最后
好了,关于HPA实验就到这里了,感谢大家阅读,最后贴上我女神的photo,祝大家生活快乐,每天都过的有意义哦,我们下期见!
智能推荐
leetcode 172. 阶乘后的零-程序员宅基地
文章浏览阅读63次。题目给定一个整数 n,返回 n! 结果尾数中零的数量。解题思路每个0都是由2 * 5得来的,相当于要求n!分解成质因子后2 * 5的数目,由于n中2的数目肯定是要大于5的数目,所以我们只需要求出n!中5的数目。C++代码class Solution {public: int trailingZeroes(int n) { ...
Day15-【Java SE进阶】IO流(一):File、IO流概述、File文件对象的创建、字节输入输出流FileInputStream FileoutputStream、释放资源。_outputstream释放-程序员宅基地
文章浏览阅读992次,点赞27次,收藏15次。UTF-8是Unicode字符集的一种编码方案,采取可变长编码方案,共分四个长度区:1个字节,2个字节,3个字节,4个字节。文件字节输入流:每次读取多个字节到字节数组中去,返回读取的字节数量,读取完毕会返回-1。注意1:字符编码时使用的字符集,和解码时使用的字符集必须一致,否则会出现乱码。定义一个与文件一样大的字节数组,一次性读取完文件的全部字节。UTF-8字符集:汉字占3个字节,英文、数字占1个字节。GBK字符集:汉字占2个字节,英文、数字占1个字节。GBK规定:汉字的第一个字节的第一位必须是1。_outputstream释放
jeecgboot重新登录_jeecg 登录自动退出-程序员宅基地
文章浏览阅读1.8k次,点赞3次,收藏3次。解决jeecgboot每次登录进去都会弹出请重新登录问题,在utils文件下找到request.js文件注释这段代码即可_jeecg 登录自动退出
数据中心供配电系统负荷计算实例分析-程序员宅基地
文章浏览阅读3.4k次。我国目前普遍采用需要系数法和二项式系数法确定用电设备的负荷,其中需要系数法是国际上普遍采用的确定计算负荷的方法,最为简便;而二项式系数法在确定设备台数较少且各台设备容量差..._数据中心用电负荷统计变压器
HTML5期末大作业:网页制作代码 网站设计——人电影网站(5页) HTML+CSS+JavaScript 学生DW网页设计作业成品 dreamweaver作业静态HTML网页设计模板_网页设计成品百度网盘-程序员宅基地
文章浏览阅读7k次,点赞4次,收藏46次。HTML5期末大作业:网页制作代码 网站设计——人电影网站(5页) HTML+CSS+JavaScript 学生DW网页设计作业成品 dreamweaver作业静态HTML网页设计模板常见网页设计作业题材有 个人、 美食、 公司、 学校、 旅游、 电商、 宠物、 电器、 茶叶、 家居、 酒店、 舞蹈、 动漫、 明星、 服装、 体育、 化妆品、 物流、 环保、 书籍、 婚纱、 军事、 游戏、 节日、 戒烟、 电影、 摄影、 文化、 家乡、 鲜花、 礼品、 汽车、 其他 等网页设计题目, A+水平作业_网页设计成品百度网盘
【Jailhouse 文章】Look Mum, no VM Exits_jailhouse sr-iov-程序员宅基地
文章浏览阅读392次。jailhouse 文章翻译,Look Mum, no VM Exits!_jailhouse sr-iov
随便推点
chatgpt赋能python:Python怎么删除文件中的某一行_python 删除文件特定几行-程序员宅基地
文章浏览阅读751次。本文由chatgpt生成,文章没有在chatgpt生成的基础上进行任何的修改。以上只是chatgpt能力的冰山一角。作为通用的Aigc大模型,只是展现它原本的实力。对于颠覆工作方式的ChatGPT,应该选择拥抱而不是抗拒,未来属于“会用”AI的人。AI职场汇报智能办公文案写作效率提升教程 专注于AI+职场+办公方向。下图是课程的整体大纲下图是AI职场汇报智能办公文案写作效率提升教程中用到的ai工具。_python 删除文件特定几行
Java过滤特殊字符的正则表达式_java正则表达式过滤特殊字符-程序员宅基地
文章浏览阅读2.1k次。【代码】Java过滤特殊字符的正则表达式。_java正则表达式过滤特殊字符
CSS中设置背景的7个属性及简写background注意点_background设置背景图片-程序员宅基地
文章浏览阅读5.7k次,点赞4次,收藏17次。css中背景的设置至关重要,也是一个难点,因为属性众多,对应的属性值也比较多,这里详细的列举了背景相关的7个属性及对应的属性值,并附上演示代码,后期要用的话,可以随时查看,那我们坐稳开车了······1: background-color 设置背景颜色2:background-image来设置背景图片- 语法:background-image:url(相对路径);-可以同时为一个元素指定背景颜色和背景图片,这样背景颜色将会作为背景图片的底色,一般情况下设置背景..._background设置背景图片
Win10 安装系统跳过创建用户,直接启用 Administrator_windows10msoobe进程-程序员宅基地
文章浏览阅读2.6k次,点赞2次,收藏8次。Win10 安装系统跳过创建用户,直接启用 Administrator_windows10msoobe进程
PyCharm2021安装教程-程序员宅基地
文章浏览阅读10w+次,点赞653次,收藏3k次。Windows安装pycharm教程新的改变功能快捷键合理的创建标题,有助于目录的生成如何改变文本的样式插入链接与图片如何插入一段漂亮的代码片生成一个适合你的列表创建一个表格设定内容居中、居左、居右SmartyPants创建一个自定义列表如何创建一个注脚注释也是必不可少的KaTeX数学公式新的甘特图功能,丰富你的文章UML 图表FLowchart流程图导出与导入导出导入下载安装PyCharm1、进入官网PyCharm的下载地址:http://www.jetbrains.com/pycharm/downl_pycharm2021
《跨境电商——速卖通搜索排名规则解析与SEO技术》一一1.1 初识速卖通的搜索引擎...-程序员宅基地
文章浏览阅读835次。本节书摘来自异步社区出版社《跨境电商——速卖通搜索排名规则解析与SEO技术》一书中的第1章,第1.1节,作者: 冯晓宁,更多章节内容可以访问云栖社区“异步社区”公众号查看。1.1 初识速卖通的搜索引擎1.1.1 初识速卖通搜索作为速卖通卖家都应该知道,速卖通经常被视为“国际版的淘宝”。那么请想一下,普通消费者在淘宝网上购买商品的时候,他的行为应该..._跨境电商 速卖通搜索排名规则解析与seo技术 pdf