PPASR语音识别(进阶级)_d:\project\ppasr-develop\models\conformer_streamin-程序员宅基地
技术标签: PaddlePaddle paddlepaddle 深度学习 语音 语音识别
PPASR语音识别(进阶级)
本项目将分三个阶段分支,分别是入门级 、进阶级 和最终级 分支,当前为进阶级,随着级别的提升,识别准确率也随之提升,也更适合实际项目使用,敬请关注!
PPASR(进阶级)基于PaddlePaddle2实现的端到端自动语音识别,相比入门级,进阶级从三个方面来提高模型的准确率,首先最主要的是更换了模型,这次采用了DeepSpeech2模型,DeepSpeech2是2015年百度发布的语音识别模型,其论文为《Baidu’s Deep Speech 2 paper》 。然后也修改了音频的预处理,这次使用了在语音识别上更好的预处理,通过用FFT energy计算线性谱图。最后修改的是解码器,相比之前使用的贪心策略解码器,这次增加了集束搜索解码器,这个解码器可以加载语言模型,对解码的结果调整,使得预测输出语句更合理,从而提高准确率。
使用环境:
- Anaconda 3
- Python 3.7
- PaddlePaddle 2.1.3
- Windows 10 or Ubuntu 18.04
安装环境
- 首先安装的是PaddlePaddle 2.1.3的GPU版本,如果已经安装过了,请跳过。
conda install paddlepaddle-gpu==2.1.3 cudatoolkit=10.2 --channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/Paddle/
- 本项目的训练在Windows或者Ubuntu都可以运行,安装环境很简单,只需要执行以下一条命令即可。
python -m pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
如果出现LLVM版本错误,则执行下面的命令,然后重新执行上面的安装命令,否则不需要执行。
cd ~
wget https://releases.llvm.org/9.0.0/llvm-9.0.0.src.tar.xz
wget http://releases.llvm.org/9.0.0/cfe-9.0.0.src.tar.xz
wget http://releases.llvm.org/9.0.0/clang-tools-extra-9.0.0.src.tar.xz
tar xvf llvm-9.0.0.src.tar.xz
tar xvf cfe-9.0.0.src.tar.xz
tar xvf clang-tools-extra-9.0.0.src.tar.xz
mv llvm-9.0.0.src llvm-src
mv cfe-9.0.0.src llvm-src/tools/clang
mv clang-tools-extra-9.0.0.src llvm-src/tools/clang/tools/extra
sudo mkdir -p /usr/local/llvm
sudo mkdir -p llvm-src/build
cd llvm-src/build
sudo cmake -G "Unix Makefiles" -DLLVM_TARGETS_TO_BUILD=X86 -DCMAKE_BUILD_TYPE="Release" -DCMAKE_INSTALL_PREFIX="/usr/local/llvm" ..
sudo make -j8
sudo make install
export LLVM_CONFIG=/usr/local/llvm/bin/llvm-config
- 在评估和预测都可以选择不同的解码器,如果是选择集束搜索解码器,就需要执行下面命令来安装环境,该解码器只支持Linux编译安装。如果使用的是Windows,那么就只能选择贪心策略解码器,无需再执行下面的命令编译安装集束搜索解码器。
cd decoders
pip3 install swig_decoders-1.2-cp37-cp37m-linux_x86_64.whl
注意: 如果不能正常安装,就需要自行编译ctc_decoders库,该编译只支持Ubuntu,其他Linux版本没测试过,执行下面命令完成编译。
cd decoders
sh setup.sh
- 下载语言模型,集束搜索解码需要使用到语言模型,下载语言模型并放在lm目录下。
cd PaddlePaddle-DeepSpeech/
mkdir lm
cd lm
wget https://deepspeech.bj.bcebos.com/zh_lm/zh_giga.no_cna_cmn.prune01244.klm
数据准备
- 在
download_data目录下是公开数据集的下载和制作训练数据列表和字典的,本项目提供了下载公开的中文普通话语音数据集,分别是Aishell,Free ST-Chinese-Mandarin-Corpus,THCHS-30 这三个数据集,总大小超过28G。下载这三个数据只需要执行一下代码即可,当然如果想快速训练,也可以只下载其中一个。
python3 download_data/aishell.py
python3 download_data/free_st_chinese_mandarin_corpus.py
python3 download_data/thchs_30.py
- 如果开发者有自己的数据集,可以使用自己的数据集进行训练,当然也可以跟上面下载的数据集一起训练。自定义的语音数据需要符合一下格式:
- 语音文件需要放在
dataset/audio/目录下,例如我们有个wav的文件夹,里面都是语音文件,我们就把这个文件存放在dataset/audio/。 - 然后把数据列表文件存在
dataset/annotation/目录下,程序会遍历这个文件下的所有数据列表文件。例如这个文件下存放一个my_audio.txt,它的内容格式如下。每一行数据包含该语音文件的相对路径和该语音文件对应的中文文本,要注意的是该中文文本只能包含纯中文,不能包含标点符号、阿拉伯数字以及英文字母。
- 语音文件需要放在
dataset/audio/wav/0175/H0175A0171.wav 我需要把空调温度调到二十度
dataset/audio/wav/0175/H0175A0377.wav 出彩中国人
dataset/audio/wav/0175/H0175A0470.wav 据克而瑞研究中心监测
dataset/audio/wav/0175/H0175A0180.wav 把温度加大到十八
- 执行下面的命令,创建数据列表,以及建立词表,也就是数据字典,把所有出现的字符都存放子在
vocabulary.txt文件中,生成的文件都存放在dataset/目录下。在图像预处理的时候需要用到均值和标准值,之后的评估和预测同样需要用到,这些都会计算并保存在文件中。
我们来说说这些文件和数据的具体作用,创建数据列表是为了在训练是读取数据,读取数据程序通过读取图像列表的每一行都能得到音频的文件路径、音频长度以及这句话的内容。通过路径读取音频文件并进行预处理,音频长度用于统计数据总长度,文字内容就是输入数据的标签,在训练是还需要数据字典把这些文字内容转置整型的数字,比如是这个字在数据字典中排在第5,那么它的标签就是4,标签从0开始。至于最后生成的均值和标准值,因为我们的数据在训练之前还需要归一化,因为每个数据的分布不一样,不同图像,最大最小值都是确定的,随机采取一部分的书籍计算均值和标准值,然后把均值和标准值保存在npy文件中。
python3 create_data.py
输出结果如下:
----------- Configuration Arguments -----------
annotation_path: dataset/annotation/
count_threshold: 0
is_change_frame_rate: True
manifest_path: dataset/manifest.train
manifest_prefix: dataset/
num_samples: -1
num_workers: 8
output_path: ./dataset/mean_std.npz
vocab_path: dataset/vocabulary.txt
------------------------------------------------
开始生成数据列表...
100%|███████████████████████| 13388/13388 [00:09<00:00, 1454.08it/s]
完成生成数据列表,数据集总长度为34.16小时!
======================================================================
开始生成噪声数据列表...
噪声音频文件为空,已跳过!
======================================================================
开始生成数据字典...
100%|██████████████████████████| 13254/13254 [00:00<00:00, 35948.64it/s]
100%|██████████████████████████| 134/134 [00:00<00:00, 35372.69it/s]
数据字典生成完成!
======================================================================
开始抽取-1条数据计算均值和标准值...
100%|█████████████████████████████| 208/208 [00:20<00:00, 9.97it/s]
计算的均值和标准值已保存在 ./dataset/mean_std.npz!
可以用使用python create_data.py --help命令查看各个参数的说明和默认值。
训练模型
- 执行训练脚本,开始训练语音识别模型, 每训练一轮保存一次模型,模型保存在
models/目录下,测试使用的是贪心解码路径解码方法。本项目支持多卡训练,通过使用--gpus参数指定,如--gpus= '0,1'指定使用第1张和第2张显卡训练。其他的参数一般不需要改动,参数--num_workers可以数据读取的线程数,这个参数是指定使用多少个线程读取数据。参数--pretrained_model是指定预训练模型所在的文件夹,使用预训练模型,在加载的时候会自动跳过维度不一致的层。如果使用--resume恢复训练模型,恢复模型的路径结构应该要跟保存的时候一样,这样才能读取到该模型是epoch数,并且必须使用跟预训练配套的数据字典,原因是,其一,数据字典的大小指定了模型的输出大小,如果使用了其他更大的数据字典,恢复训练模型就无法完全加载。其二,数值字典定义了文字的ID,不同的数据字典文字的ID可能不一样,这样恢复练模型的作用就不是那么大了。
# 单卡训练
python3 train.py
# 多卡训练
python -m paddle.distributed.launch --gpus '0,1' train.py
训练输出结果如下:
----------- Configuration Arguments -----------
augment_conf_path: conf/augmentation.json
batch_size: 16
dataset_vocab: dataset/vocabulary.txt
learning_rate: 0.0005
max_duration: 20
mean_std_path: dataset/mean_std.npz
min_duration: 0
num_conv_layers: 2
num_epoch: 50
num_rnn_layers: 3
num_workers: 8
pretrained_model: None
resume_model: None
rnn_layer_size: 1024
save_model: models/
test_manifest: dataset/manifest.test
train_manifest: dataset/manifest.train
------------------------------------------------
----------------------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
========================================================================================
Conv2D-1 [[1, 1, 161, 970]] [1, 32, 81, 324] 14,464
BatchNorm2D-1 [[1, 32, 81, 324]] [1, 32, 81, 324] 128
Hardtanh-1 [[1, 32, 81, 324]] [1, 32, 81, 324] 0
MaskConv-1 [[1, 32, 81, 324], [1]] [1, 32, 81, 324] 0
ConvBn-1 [[1, 1, 161, 970], [1]] [[1, 32, 81, 324], [1]] 0
Conv2D-2 [[1, 32, 81, 324]] [1, 32, 41, 324] 236,576
BatchNorm2D-2 [[1, 32, 41, 324]] [1, 32, 41, 324] 128
Hardtanh-2 [[1, 32, 41, 324]] [1, 32, 41, 324] 0
MaskConv-2 [[1, 32, 41, 324], [1]] [1, 32, 41, 324] 0
ConvBn-2 [[1, 32, 81, 324], [1]] [[1, 32, 41, 324], [1]] 0
ConvStack-1 [[1, 1, 161, 970], [1]] [[1, 32, 41, 324], [1]] 0
Linear-1 [[1, 324, 1312]] [1, 324, 3072] 4,033,536
BatchNorm1D-1 [[1, 324, 3072]] [1, 324, 3072] 12,288
GRU-1 [] [[1, 324, 2048], [2, 1, 1024]] 25,178,112
MaskRNN-1 [[1, 324, 2048], [1]] [1, 324, 2048] 0
BiGRUWithBN-1 [[1, 324, 1312], [1]] [1, 324, 2048] 0
Linear-2 [[1, 324, 2048]] [1, 324, 3072] 6,294,528
BatchNorm1D-2 [[1, 324, 3072]] [1, 324, 3072] 12,288
GRU-2 [] [[1, 324, 2048], [2, 1, 1024]] 25,178,112
MaskRNN-2 [[1, 324, 2048], [1]] [1, 324, 2048] 0
BiGRUWithBN-2 [[1, 324, 2048], [1]] [1, 324, 2048] 0
Linear-3 [[1, 324, 2048]] [1, 324, 3072] 6,294,528
BatchNorm1D-3 [[1, 324, 3072]] [1, 324, 3072] 12,288
GRU-3 [] [[1, 324, 2048], [2, 1, 1024]] 25,178,112
MaskRNN-3 [[1, 324, 2048], [1]] [1, 324, 2048] 0
BiGRUWithBN-3 [[1, 324, 2048], [1]] [1, 324, 2048] 0
RNNStack-1 [[1, 324, 1312], [1]] [1, 324, 2048] 0
BatchNorm1D-4 [[1, 324, 2048]] [1, 324, 2048] 8,192
Linear-4 [[1, 324, 2048]] [1, 324, 2882] 5,905,218
========================================================================================
Total params: 98,358,498
Trainable params: 98,313,186
Non-trainable params: 45,312
----------------------------------------------------------------------------------------
Input size (MB): 0.60
Forward/backward pass size (MB): 159.92
Params size (MB): 375.21
Estimated Total Size (MB): 535.72
----------------------------------------------------------------------------------------
[2021-09-17 10:46:03.117764] 训练数据:13254
............
[2021-09-17 08:41:16.135825] Train epoch: [24/50], batch: [5900/6349], loss: 3.84609, learning rate: 0.00000688, eta: 10:38:40
[2021-09-17 08:41:38.698795] Train epoch: [24/50], batch: [6000/6349], loss: 0.92967, learning rate: 0.00000688, eta: 8:42:11
[2021-09-17 08:42:04.166192] Train epoch: [24/50], batch: [6100/6349], loss: 2.05670, learning rate: 0.00000688, eta: 10:59:51
[2021-09-17 08:42:26.471328] Train epoch: [24/50], batch: [6200/6349], loss: 3.03502, learning rate: 0.00000688, eta: 11:51:28
[2021-09-17 08:42:50.002897] Train epoch: [24/50], batch: [6300/6349], loss: 2.49653, learning rate: 0.00000688, eta: 12:01:30
======================================================================
[2021-09-17 08:43:01.954403] Test batch: [0/65], loss: 13.76276, cer: 0.23105
[2021-09-17 08:43:07.817434] Test epoch: 24, time/epoch: 0:24:30.756875, loss: 6.90274, cer: 0.15213
======================================================================
可以用使用python train.py --help命令查看各个参数的说明和默认值。
- 在训练过程中,程序会使用VisualDL记录训练结果,可以通过以下的命令启动VisualDL。
visualdl --logdir=log --host 0.0.0.0
- 然后再浏览器上访问
http://localhost:8040可以查看结果显示,如下。
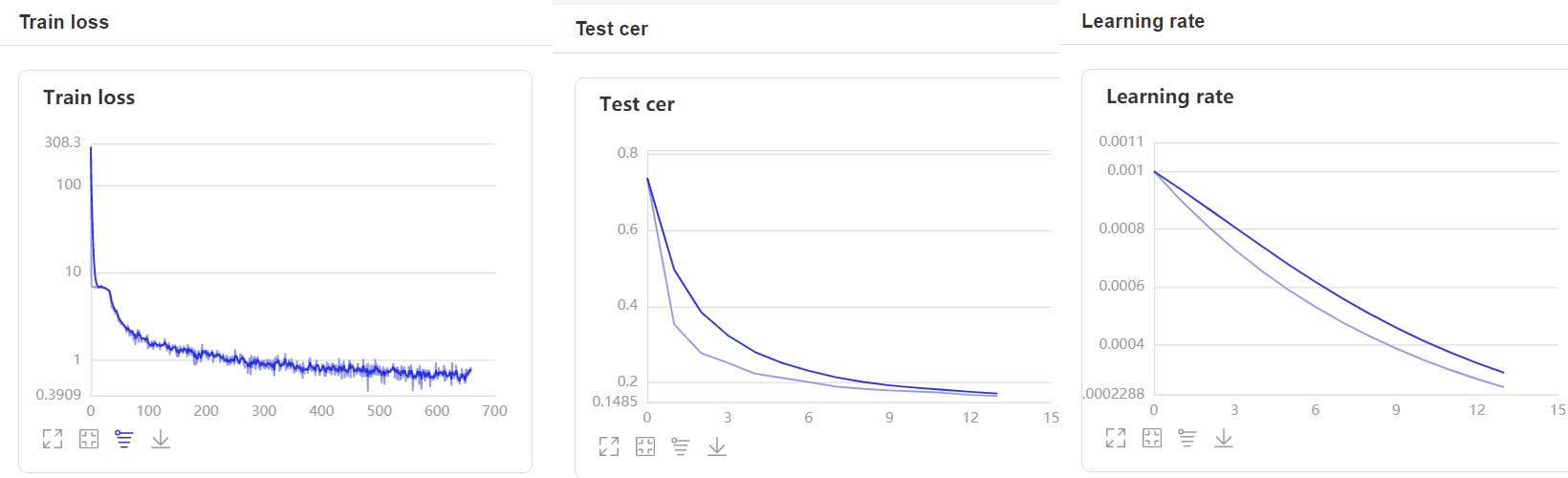
评估
在评估和预测中,使用--decoder参数可以指定解码方法,当--decoder参数为ctc_greedy对结果解码的贪心策略解码方法,贪心策略是在每一步选择概率最大的输出值,然后删除重复字符和空索引,就得到预测结果了。当--decoder参数为ctc_beam_search对结果解码的集束搜索解码方法,该方法可以加载语言模型,将模型输出的结果在语音模型中搜索最优解。
- 我们可以使用这个脚本对模型进行评估,通过字符错误率来评价模型的性能。参数
--decoder默认指定集束搜索解码方法对结果进行解码,读者也可以使用贪心策略解码方法,对比他们的解码的准确率。参数--mean_std_path指定均值和标准值得文件,这个文件需要跟训练时使用的是同一个文件。参数--beam_size指定集束搜索方法的搜索宽度,越大解码结果越准确,但是解码速度就越慢。参数--model_path指定模型所在的文件夹的路径。
python3 eval.py --model_path=models/epoch_50/
可以用使用python eval.py --help命令查看各个参数的说明和默认值。
导出模型
在训练时,我们保存了模型的参数,但是如何要用于推理,还需要导出预测模型,执行下面命令导出模型。模型的结构参数必须跟训练时的一致。
python export_model.py --resume=models/epoch_50/
可以用使用python export_model.py --help命令查看各个参数的说明和默认值。
预测
- 我们可以使用这个脚本使用模型进行预测,通过传递音频文件的路径进行识别。参数
--decoder默认指定集束搜索解码方法对结果进行解码,读者也可以使用贪心策略解码方法,对比他们的解码的准确率。参数--mean_std_path指定均值和标准值得文件,这个文件需要跟训练时使用的是同一个文件。参数--beam_size指定集束搜索方法的搜索宽度,越大解码结果越准确,但是解码速度就越慢。参数model_path指定模型所在的文件夹的路径,参数wav_path指定需要预测音频文件的路径。
python3 infer.py --audio_path=dataset/test.wav
可以用使用python infer.py --help命令查看各个参数的说明和默认值。
模型下载
| 数据集 | 卷积层数量 | 循环神经网络的数量 | 循环神经网络的大小 | 测试集字错率 | 下载地址 |
|---|---|---|---|---|---|
| aishell(179小时) | 2 | 3 | 1024 | 0.083327 | 点击下载 |
| free_st_chinese_mandarin_corpus(109小时) | 2 | 3 | 1024 | 0.143291 | 点击下载 |
| thchs_30(34小时) | 2 | 3 | 1024 | 0.047665 | 点击下载 |
说明: 这里提供的是训练参数,如果要用于预测,还需要执行导出模型,使用的解码方法是集束搜索。
智能推荐
5个超厉害的资源搜索网站,每一款都可以让你的资源满满!_最全资源搜索引擎-程序员宅基地
文章浏览阅读1.6w次,点赞8次,收藏41次。生活中我们无时不刻不都要在网站搜索资源,但就是缺少一个趁手的资源搜索网站,如果有一个比较好的资源搜索网站可以帮助我们节省一大半时间!今天小编在这里为大家分享5款超厉害的资源搜索网站,每一款都可以让你的资源丰富精彩!网盘传奇一款最有效的网盘资源搜索网站你还在为找网站里面的资源而烦恼找不到什么合适的工具而烦恼吗?这款网站传奇网站汇聚了4853w个资源,并且它每一天都会持续更新资源;..._最全资源搜索引擎
Book类的设计(Java)_6-1 book类的设计java-程序员宅基地
文章浏览阅读4.5k次,点赞5次,收藏18次。阅读测试程序,设计一个Book类。函数接口定义:class Book{}该类有 四个私有属性 分别是 书籍名称、 价格、 作者、 出版年份,以及相应的set 与get方法;该类有一个含有四个参数的构造方法,这四个参数依次是 书籍名称、 价格、 作者、 出版年份 。裁判测试程序样例:import java.util.*;public class Main { public static void main(String[] args) { List <Book>_6-1 book类的设计java
基于微信小程序的校园导航小程序设计与实现_校园导航微信小程序系统的设计与实现-程序员宅基地
文章浏览阅读613次,点赞28次,收藏27次。相比于以前的传统手工管理方式,智能化的管理方式可以大幅降低学校的运营人员成本,实现了校园导航的标准化、制度化、程序化的管理,有效地防止了校园导航的随意管理,提高了信息的处理速度和精确度,能够及时、准确地查询和修正建筑速看等信息。课题主要采用微信小程序、SpringBoot架构技术,前端以小程序页面呈现给学生,结合后台java语言使页面更加完善,后台使用MySQL数据库进行数据存储。微信小程序主要包括学生信息、校园简介、建筑速看、系统信息等功能,从而实现智能化的管理方式,提高工作效率。
有状态和无状态登录
传统上用户登陆状态会以 Session 的形式保存在服务器上,而 Session ID 则保存在前端的 Cookie 中;而使用 JWT 以后,用户的认证信息将会以 Token 的形式保存在前端,服务器不需要保存任何的用户状态,这也就是为什么 JWT 被称为无状态登陆的原因,无状态登陆最大的优势就是完美支持分布式部署,可以使用一个 Token 发送给不同的服务器,而所有的服务器都会返回同样的结果。有状态和无状态最大的区别就是服务端会不会保存客户端的信息。
九大角度全方位对比Android、iOS开发_ios 开发角度-程序员宅基地
文章浏览阅读784次。发表于10小时前| 2674次阅读| 来源TechCrunch| 19 条评论| 作者Jon EvansiOSAndroid应用开发产品编程语言JavaObjective-C摘要:即便Android市场份额已经超过80%,对于开发者来说,使用哪一个平台做开发仍然很难选择。本文从开发环境、配置、UX设计、语言、API、网络、分享、碎片化、发布等九个方面把Android和iOS_ios 开发角度
搜索引擎的发展历史
搜索引擎的发展历史可以追溯到20世纪90年代初,随着互联网的快速发展和信息量的急剧增加,人们开始感受到了获取和管理信息的挑战。这些阶段展示了搜索引擎在技术和商业模式上的不断演进,以满足用户对信息获取的不断增长的需求。
随便推点
控制对象的特性_控制对象特性-程序员宅基地
文章浏览阅读990次。对象特性是指控制对象的输出参数和输入参数之间的相互作用规律。放大系数K描述控制对象特性的静态特性参数。它的意义是:输出量的变化量和输入量的变化量之比。时间常数T当输入量发生变化后,所引起输出量变化的快慢。(动态参数) ..._控制对象特性
FRP搭建内网穿透(亲测有效)_locyanfrp-程序员宅基地
文章浏览阅读5.7w次,点赞50次,收藏276次。FRP搭建内网穿透1.概述:frp可以通过有公网IP的的服务器将内网的主机暴露给互联网,从而实现通过外网能直接访问到内网主机;frp有服务端和客户端,服务端需要装在有公网ip的服务器上,客户端装在内网主机上。2.简单的图解:3.准备工作:1.一个域名(www.test.xyz)2.一台有公网IP的服务器(阿里云、腾讯云等都行)3.一台内网主机4.下载frp,选择适合的版本下载解压如下:我这里服务器端和客户端都放在了/usr/local/frp/目录下4.执行命令# 服务器端给执_locyanfrp
UVA 12534 - Binary Matrix 2 (网络流‘最小费用最大流’ZKW)_uva12534-程序员宅基地
文章浏览阅读687次。题目:http://acm.hust.edu.cn/vjudge/contest/view.action?cid=93745#problem/A题意:给出r*c的01矩阵,可以翻转格子使得0表成1,1变成0,求出最小的步数使得每一行中1的个数相等,每一列中1的个数相等。思路:网络流。容量可以保证每一行和每一列的1的个数相等,费用可以算出最小步数。行向列建边,如果该格子是_uva12534
免费SSL证书_csdn alphassl免费申请-程序员宅基地
文章浏览阅读504次。1、Let's Encrypt 90天,支持泛域名2、Buypass:https://www.buypass.com/ssl/resources/go-ssl-technical-specification6个月,单域名3、AlwaysOnSLL:https://alwaysonssl.com/ 1年,单域名 可参考蜗牛(wn789)4、TrustAsia5、Alpha..._csdn alphassl免费申请
测试算法的性能(以选择排序为例)_算法性能测试-程序员宅基地
文章浏览阅读1.6k次。测试算法的性能 很多时候我们需要对算法的性能进行测试,最简单的方式是看算法在特定的数据集上的执行时间,简单的测试算法性能的函数实现见testSort()。【思想】:用clock_t计算某排序算法所需的时间,(endTime - startTime)/ CLOCKS_PER_SEC来表示执行了多少秒。【关于宏CLOCKS_PER_SEC】:以下摘自百度百科,“CLOCKS_PE_算法性能测试
Lane Detection_lanedetectionlite-程序员宅基地
文章浏览阅读1.2k次。fromhttps://towardsdatascience.com/finding-lane-lines-simple-pipeline-for-lane-detection-d02b62e7572bIdentifying lanes of the road is very common task that human driver performs. This is important ..._lanedetectionlite