机器学习基础知识-程序员宅基地
机器学习(Machine Learning) 是让计算机能够自动地从某些数据中总结出规律,并得出某种预测模型,进而利用该模型对未知数据进行预测的方法。它是一种实现人工智能的方式,是一门交叉学科,综合了统计学、概率论、逼近论、凸分析、计算复杂性理论等。
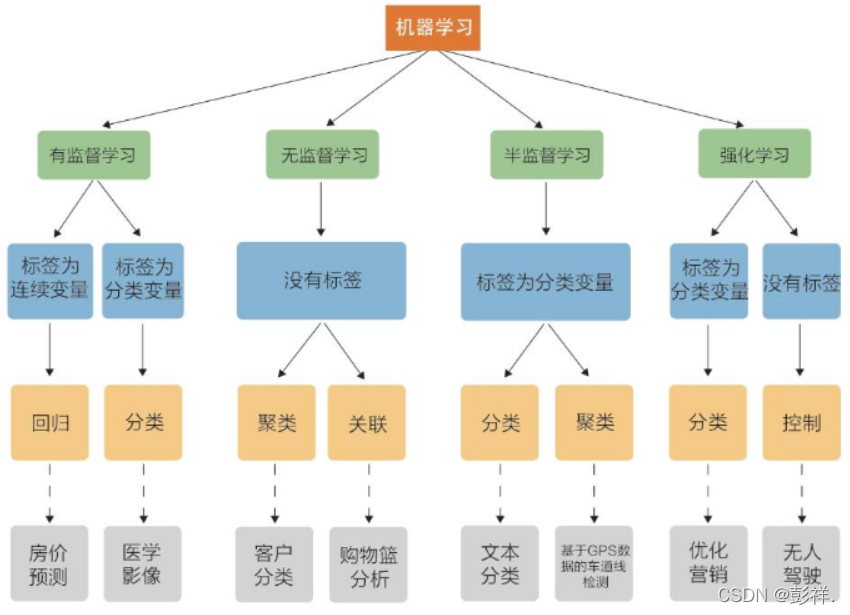
机器学习分类
目前,机器学习大致可以分为以下几类:
(1) 有监督学习(Supervised Learning) :当我们已经拥有–些数据及数据对应的类标时,就可以通过这些数据训练出一个模型,再利用这个模型去预测新数据的类标,这种情况称为有监督学习。有监督学习可分为回归问题和分类问题两大类。在回归问题中,我们预测的结果是连续值;而在分类问题中,我们预测的结果是离散值。常见的有监督学习算法包括线性回归、逻辑回归、K-近邻、朴素贝叶斯、决策树、随机森林、支持向量机等。
(2) 无监督学习(Unsupervised Learning):在无监督学习中是没有给定类标训练样本的,这就需要我们对给定的数据直接建模。常见的无监督学习算法包括K-means、EM算法等。
(3) 半监督学习(Semi-supervised Learn-ing):半监督学习介于有监督学习和无监督学习之间,给定的数据集既包括有类标的数据,也包括没有类标的数据,需要在工作量(例如数据的打标)和模型的准确率之间取一个平衡点。
(4)强化学习( Reinforcement Learning):从不懂到通过不断学习、总结规律,最终学会的过程便是强化学习。强化学习很依赖于学习的“周围环境”,强调如何基于“周围环境”而做出相应的动作。
机器学习的一般流程
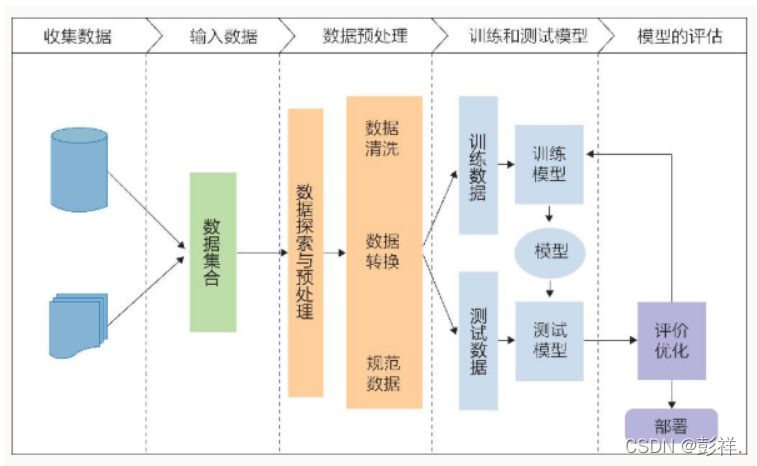
一个机器学习任务的成功与否往往在很大程度上取决于特征工程。简单来说,特征工程的任务是从原始数据中抽出最具代表性的特征,从而让模型能够更有效地学习这些数据。通常我们可以使用scikit-learn这个库来处理数据和提取特征,scikit-learn是机器学习中使用非常广泛的第三方模块,本身封装了很多常用的机器学习算法,同时还有很多数据处理和特征提取相关的方法。
数据预处理
根据数据类型的不同,数据预处理的方式和内容也不尽相同,这里简单介绍几种较常用的方式。**
(1)归一化
归一化指将不同变化范围内的值映射到一个固定的范围里,例如,常使用min-max等方法将数值归一化到[0,1]的区间内(有些时候也会归一化到[-1,1]的区间内)。归一化的作用包括无量纲化一、加快模型的收敛速度,以及避免小数值的特征被忽略等。
(2)标准化
标准化指在不改变数据原分布的前提下,将数据按比例缩放,使之落入一个限定的区间,让数据之间具有可比性。需要注意的是,归一化和标准化各有其适用的情况,例如在涉及距离度量或者数据符合正态分布的时候,应该使用标准化而不是归一化。常用的标准化方法有z- score等。
(3)离散化
离散化指把连续的数值型数据进行分段,可采用相等步长或相等频率等方法对落在每一个分段内的数值型数据赋予一个新的统一的符号或数值。离散化是为了适应模型的需要,有助于消除异常数据,提高算法的效率。
(4)二值化
二值化指将数值型数据转换为0和1两个值,例如通过设定一个阈值,当特征的值大于该阈值时转换为1,当特征的值小于或等于该阈值时转换为0。二值化的目的在于简化数据,有些时候还可以消除数据(例如图像数据)中的“杂音”。
特征工程
特征工程的目的是把原始的数据转换为模型可用的数据,主要包括三个子问题:特征构造、特征提取和特征选择。
特征构造一般是在原有特征的基础上做“组合”操作,例如,对原有特征进行四则运算,从而得到新的特征。
特征提取指使用映射或变换的方法将维数较高的原始特征转换为维数较低的新的特征。如主成分分析
特征选择即从原始的特征中挑选出一些具有代表性、使模型效果更好的特征。
其中,特征提取和特征选择最为常用。
模型性能判别与选择
基础概念
在分类任务中,通常把错分的样本数占样本总数的比例称为错误率(error rate)。比如m个样本有a个预测错了,错误率就是 E = a/m;与错误率相对的 1 - a/m 称为精度(accuracy),或者说正确率,数值上 精度 = 1 - 错误率。
更一般地,我们通常会把学习器的实际预测输出与样本的真实输出之间的差异称为误差(error)。学习器在训练集上的误差称为训练误差(training error)或者经验误差(empirical error)。而在新样本上的误差则称为泛化误差(generalization error)或者测试误差(test error;)。显然,我们希望得到泛化误差小的学习器。所以我们希望模型的泛化误差尽可能小,但现实是,我们无法知道新样本是怎样的,所以只能尽可能地利用训练数据来最小化经验误差。
L loss function 损失函数



过(欠)拟合
对于经验误差很小,而在新样本中泛化误差很大的情况,多是由于在测试集中将训练样本中的一些本身特征看作为整个样本空间的特征,从而导致泛化能力下降。而欠拟合则是相反。
有多种因素可能导致过拟合,其中最常见的情况是由于学习能力过于强大,以至于把训练样本所包含的不太一般的特性都学到了,而欠拟合则通常是由于学习能力低下而造成的。
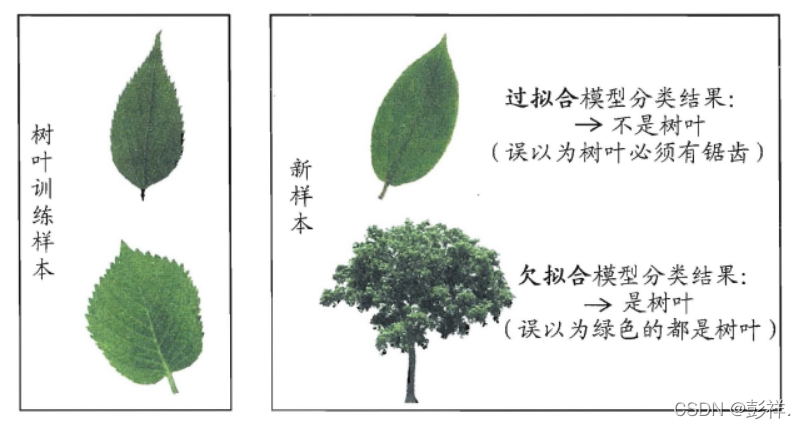
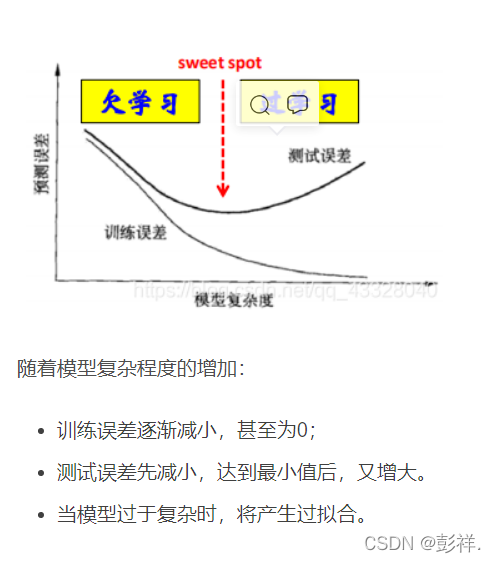
欠拟合比较容易克服,只要适当地增加模型复杂度(比方说增加神经网络的层数或者训练轮数,扩展决策树学习中的分支)就好。但过拟合是无法彻底避免的,我们所能做的只是缓解,或者说减小其风险(比如减少模型复杂度/增加训练数据),这也是机器学习发展中的一个关键阻碍。
这样,在学习时就要防止过拟合,进行最优的模型选择,即选择复杂度相当的模型,以达到使测试误差最小的学习目的。下面介绍几种常用的模型选择方法。
留出法,正则化,交叉验证,自助法
模型性能评价
错误率与精度
查准率,查全率,F1,P-R曲线


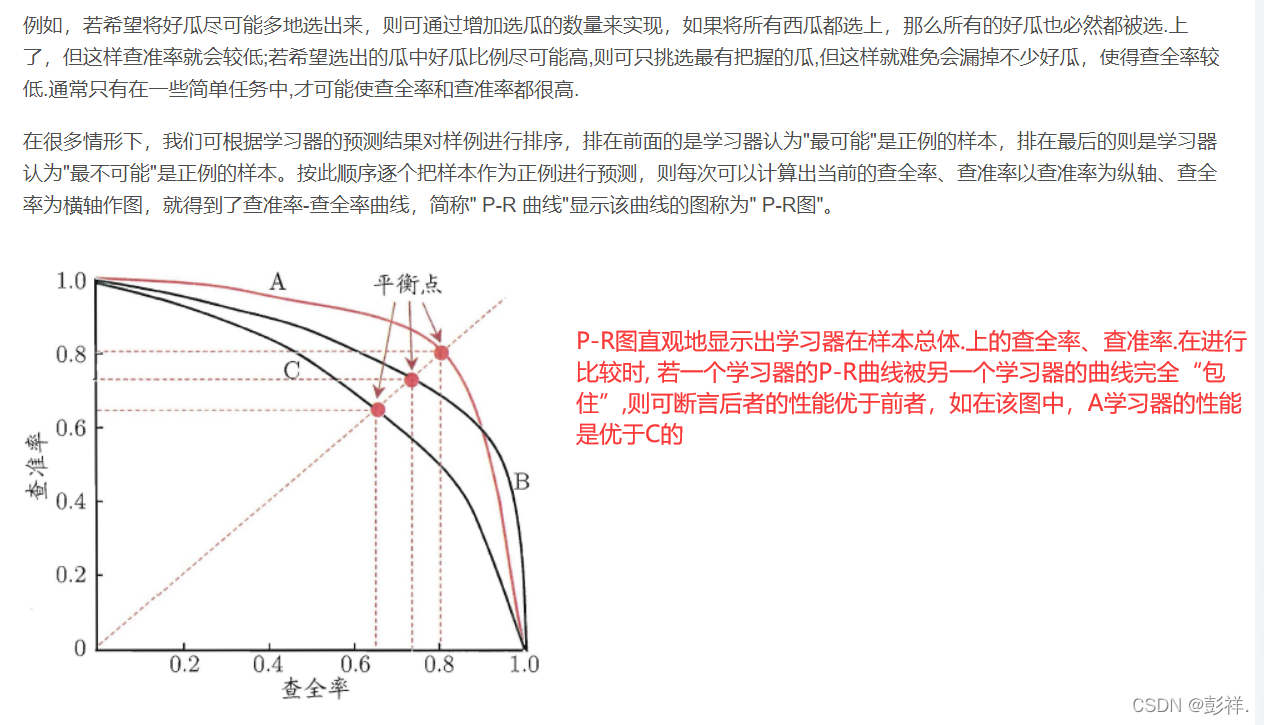
ROC曲线
在不同的应用任务中,我们可根据任务需求来采用不同的截断点,例如若我们更重视“查准率”,则可选择排序中靠前的位置进行截断;若更重视“查全率",则可选择靠后的位置进行截断.因此,排序本身的质量好坏,体现了综合考虑学习器在不同任务下的“期望泛化性能”的好坏,或者说,“一般情况下”泛化性能的好坏. ROC曲线则是从这个角度出发来研究学习器泛化性能的有力工具.
ROC曲线的纵轴是“真正例率”(True Positive Rate,简称TPR),横轴是“假正例率”(False PositiveRate,简称FPR)
智能推荐
Maven编译打包项目 mvn clean install报错ERROR_mvn clean install有errors-程序员宅基地
文章浏览阅读1.1k次。在项目的target文件夹下把之前"mvn clean package"生成的压缩包(我的是jar包)删掉重新执行"mvn clean package"再执行"mvn clean install"即可_mvn clean install有errors
navacate连接不上mysql_navicat连接mysql失败怎么办-程序员宅基地
文章浏览阅读974次。Navicat连接mysql数据库时,不断报1405错误,下面是针对这个的解决办法:MySQL服务器正在运行,停止它。如果是作为Windows服务运行的服务器,进入计算机管理--->服务和应用程序------>服务。如果服务器不是作为服务而运行的,可能需要使用任务管理器来强制停止它。创建1个文本文件(此处命名为mysql-init.txt),并将下述命令置于单一行中:SET PASSW..._nvarchar链接不上数据库
Python的requests参数及方法_python requests 参数-程序员宅基地
文章浏览阅读2.2k次。Python的requests模块是一个常用的HTTP库,用于发送HTTP请求和处理响应。_python requests 参数
近5年典型的的APT攻击事件_2010谷歌网络被极光黑客攻击-程序员宅基地
文章浏览阅读2.7w次,点赞7次,收藏50次。APT攻击APT攻击是近几年来出现的一种高级攻击,具有难检测、持续时间长和攻击目标明确等特征。本文中,整理了近年来比较典型的几个APT攻击,并其攻击过程做了分析(为了加深自己对APT攻击的理解和学习)Google极光攻击2010年的Google Aurora(极光)攻击是一个十分著名的APT攻击。Google的一名雇员点击即时消息中的一条恶意链接,引发了一系列事件导致这个搜_2010谷歌网络被极光黑客攻击
Android 开发的现状及发展前景_android现状-程序员宅基地
文章浏览阅读8.8k次,点赞3次,收藏31次。在几年前的时候,曾听过很多人说 Android 学习很简单,做个App就上手了,工作机会多,毕业后也比较容易找工作。这种观点可能是很多Android开发者最开始入行的原因之一。在工作初期,工作主要是按照业务需求实现App页面的功能,按照设计师的设计稿实现页面的效果。在实现的过程中,总是会被提如下的需求:这个字能不能大点或者醒目点儿?感觉颜色和设计稿有差别,能不能再调调?怎么老是崩溃啊,行不行啊?…所以,工作过一、两年后你会发现,自己每天重复工作内容就是将找各种各样的组件、框架,拖拖拽拽,改_android现状
php获取当月天数及当月第一天及最后一天、上月第一天及最后一天实现方法_php 判断是否月最后一天取上月月份-程序员宅基地
文章浏览阅读274次。在做查询过程中,例如要实现查上个月从第一天到最后一天的佣金(提成),那我们在程序实现过程中就要让程序在上个月的范围内查询,第一天是比较好办,但最后一天就不定,要去写段函数进行月份及年份判断来得出上个月共有多少天.那就比麻烦,还有获取当前月份,当前年份等常规日期获取函数,以下代码都是经过本公司工程师测试后的正确代码,可以放心使用. 1.获取上个月第一天及最后一天. echo date('_php 判断是否月最后一天取上月月份
随便推点
uploadify2.1.4如何能使按钮显示中文-程序员宅基地
文章浏览阅读48次。uploadify2.1.4如何能使按钮显示中文博客分类:uploadify网上关于这段话的搜索恐怕是太多了。方法多也试过了不知怎么,反正不行。最终自己想办法给解决了。当然首先还是要有fla源码。直接去管网就可以下载。[url]http://www.uploadify.com/wp-content/uploads/uploadify-v2.1.4...
戴尔服务器安装VMware ESXI6.7.0教程(U盘安装)_vmware-vcsa-all-6.7.0-8169922.iso-程序员宅基地
文章浏览阅读9.6k次,点赞5次,收藏36次。戴尔服务器安装VMware ESXI6.7.0教程(U盘安装)一、前期准备1、下载镜像下载esxi6.7镜像:VMware-VMvisor-Installer-6.7.0-8169922.x86_64.iso这里推荐到戴尔官网下载,Baidu搜索“戴尔驱动下载”,选择进入官网,根据提示输入服务器型号搜索适用于该型号服务器的所有驱动下一步选择具体类型的驱动选择一项下载即可待下载完成后打开软碟通(UItraISO),在“文件”选项中打开刚才下载好的镜像文件然后选择启动_vmware-vcsa-all-6.7.0-8169922.iso
百度语音技术永久免费的语音自动转字幕介绍 -程序员宅基地
文章浏览阅读2k次。百度语音技术永久免费的语音自动转字幕介绍基于百度语音技术,识别率97%无时长限制,无文件大小限制永久免费,简单,易用,速度快支持中文,英文,粤语永久免费的语音转字幕网站: http://thinktothings.com视频介绍 https://www.bilibili.com/video/av42750807 ...
Dyninst学习笔记-程序员宅基地
文章浏览阅读7.6k次,点赞2次,收藏9次。Instrumentation是一种直接修改程序二进制文件的方法。其可以用于程序的调试,优化,安全等等。对这个词一般的翻译是“插桩”,但这更多使用于软件测试领域。【找一些相关的例子】Dyninst可以动态或静态的修改程序的二进制代码。动态修改是在目标进程运行时插入代码(dynamic binary instrumentation)。静态修改则是直接向二进制文件插入代码(static b_dyninst
在服务器上部署asp网站,部署asp网站到云服务器-程序员宅基地
文章浏览阅读2.9k次。部署asp网站到云服务器 内容精选换一换通常情况下,需要结合客户的实际业务环境和具体需求进行业务改造评估,建议您进行服务咨询。这里仅描述一些通用的策略供您参考,主要分如下几方面进行考虑:业务迁移不管您的业务是否已经上线华为云,业务迁移的策略是一致的。建议您将时延敏感型,有快速批量就近部署需求的业务迁移至IEC;保留数据量大,且需要长期稳定运行的业务在中心云上。迁移方法请参见如何计算隔离独享计算资源..._nas asp网站
android开发之bitmap转数组的方法-程序员宅基地
文章浏览阅读4.7k次。/** 方法一 * 将bitmap转为数组的方法 * * @param bitmap 图片 * @return 返回数组 */ public byte[] getBytesByBitmap(Bitmap bitmap) { ByteBuffer buffer = ByteBuffer.allocate(bitmap.ge..._bitmap转数组