【Java项目】1000w数据量的表如何做到快速的关键字检索?_java千万数据量查询-程序员宅基地
技术标签: 算法 java elasticsearch mysql 数据结构
需求
ok,这个需求是我提的,然后我问了我的一位杭州的朋友,然后我们最后一起敲定这个方法。
我的项目有一个根据关键字进行商品名称的搜索功能,用户输入部分关键字之后,那么就需要查询出这个关键字对应的所有商品。假设我现在有1000w行记录,并且不能使用ES做倒排索引解决这个问题。
那么你会如何解决这个问题?
我们先分析,如果我们使用数据库提供的 % 这种模糊匹配机制,首先我们的索引会失效,并且这基本意味着会走全表扫描,对于1000w行的记录如果我们走全表扫描,那么效率可想而知。
并且如果使用分库分表技术,那么维护的难度也大了,不论是业务代码还是数据库都得跟着修改,非常麻烦,那么如何解决这个问题?
解决思路
基本设计
大概流程如下:
我们可以自己实现一个倒排索引的算法,用户创建商品之后,将商品名称进行细粒度的分词,比如输入 “Java技术指导”,那么分词为“Java”,“技术”,“指导”。粒度越细越好。
可以看到此时我们得到的是一个数组,对吧。
然后我们创建两张表,一张表是商品表,存储商品的完整信息。
另一张表是倒排索引表,里面是什么内容?
包括id,word,goods_ids
这里的word就是我们的分词数据,goods_ids也就是我们这个关键字下面对应的所有商品id。
上面我们对一个字符串进行分词后得到的,其实是一个数组对吧,那么我们此时就可以向数据库中插入这三行的数据了,大概格式如下。
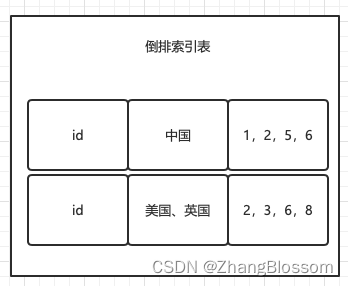
然后我们得到goods_ids是一个集合,我们在使用这个集合去商品表中查询出所有在这个集合中的记录即可。
查询流程
那么我现在大概简述一下一个数据的查询流程:
我们查询一个商品,通过关键字的方式,经过倒排索引的算法得到word值,去数据库中查询是否有这个word值,如果有,那么直接查询出来这个关键字对应的goods_ids这一段字符串,我们对字符串进行处理得到字符串包含的所有id,然后用这些id去商品表查询数据即可。
ok,那么如果有插入和修改,删除等操作怎么办呢?
插入流程
先说插入流程,一样的,当我们要插入一个数据的时候,我们先得到这个商品对应的word,也就是我们取出商品的name商品名称字段,然后对这个name字段进行分词算法,得到细粒度的分词。之后,我们我们将这个记录插入到商品表中,得到插入的id之后,返回id成功后,我们在将分词得到的数组,配合上我们得到的商品id,循环的去插入到这个分词表中,如果分词表中出现了重复的word,那么我们做的是取出goods_ids这个字段,然后再字段尾巴上补上这个id,而如果不存在这个字段,则新建一行记录,word为当前分词,goods_ids直接为刚才返回的id。
修改流程
修改流程其实已经和上面的流程差不多了,依旧是经过分词,然后去精确判断分词对应的行,然后修改对应的ids字段即可。
当然,其实没有必要这样子,因为会让代码更加复杂,我们只需要拿到所有的id之后,去商品表中判断的时候判断删除标志位即可,也就是使用逻辑删除即可。
删除流程
删除流程也差不多,只不过我们如何删除对应的goods_ids中的哪一个id呢?
我们首先取出goods_ids这个字段值,然后通过 “ ,”分隔符得到每一个id,然后我们删除指定的id即可,当然,为了加快速度,我们的商品表中的id是自增的,所以这样子就能尽可能快的删除指定数据了。
优化思路
其实,顺着上面的思路,我忽然想到。其实我们的数据库其实作用就是为了保存一个分词,然后分词后面对应的是一堆的id,这些id是字符串,也就是我们取出来之后还得先经过处理才能得到真正可用的id。
我想的是,上面的结构其实很简单,就是一个 word—goods_ids的结构,这种结构用Redis肯定可以呀对吧。
但是如果你直接K-V结构或者hash,那么结构其实相当于就是把磁盘空间变成了内存空间,我觉得也没有多好。当然,处理起来可能比刚才那个转字符串完毕之后,然后再查询来的快。
然后我就我想到了我常用的Bitmap结构,0101啊,对吧,我只需要把如果说存在这个id,那么我把对应的位置置1即可,这样子增删改的速度全都加快了不是嘛。
当然,有一个缺点就是,查询Redis是有网络开销的。
但是我觉得如果使用Redis的bitmap,那么由于增删改查的速度都更快了,并且也不需要字符串的处理了,可能效果更优。
当然,也可以直接使用Java提供的BitSet。
但是我实现了一下发现,BitSet的缺点在于,我不能很快的得到到底那些索引位为1,我需要不断的通过位运算的方式才能得到为1的位。
Redis的问题在于,如果我使用RedisTemplate然后去获取bitmap结构整个结构,会报错,就导致我依旧可能需要去循环遍历每个可能位1的位。
代码实现
代码单纯只是为了验证这种方式的可行性,对于数据库字段的设计,以及其他性能方面的考虑,代码方面的优化都还没有做。大致代码如下:
POJO类
@Data
@TableName("goods")
@AllArgsConstructor
@NoArgsConstructor
public class Goods implements Serializable {
private static final long serialVersionUID = 1L;
/**
* 主键
*/
@TableId(value = "id", type = IdType.AUTO)
private Long id;
private String goodName;
@TableLogic(value = "false", delval = "true")
private boolean deleted;
}
@Data
@TableName("word_goods")
public class WordGoods implements Serializable {
private static final long serialVersionUID = 1L;
/**
* 主键
*/
@TableId(value = "id", type = IdType.AUTO)
private Long id;
private String goodsId;
private String word;
}
Service代码
package ebuy.campus.deal.service.impl;
import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import ebuy.campus.deal.mapper.GoodsMapper;
import ebuy.campus.deal.mapper.WordGoodsMapper;
import ebuy.campus.deal.model.pojo.Goods;
import ebuy.campus.deal.model.pojo.WordGoods;
import ebuy.campus.deal.service.GoodsService;
import ebuy.campus.framework.core.constant.DealConstant;
import ebuy.campus.framework.core.util.HanLPUtil;
import ebuy.campus.framework.redis.service.RedisService;
import org.jetbrains.annotations.NotNull;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.io.IOException;
import java.util.*;
/**
* @author: 张锦标
* @date: 2023/6/13 15:26
* GoodsServiceImpl类
*/
@Service
public class GoodsServiceImpl implements GoodsService {
@Autowired
private GoodsMapper goodsMapper;
@Autowired
private WordGoodsMapper wordGoodsMapper;
@Autowired
private RedisService redisService;
@Transactional
public boolean add(Goods goods) {
try {
//分词操作
List<String> texts = HanLPUtil.parse(goods.getGoodName());
//取出数据库中包含该分词的所有行
LambdaQueryWrapper<WordGoods> lqw = new LambdaQueryWrapper<>();
lqw.in(WordGoods::getWord, texts.toArray());
List<WordGoods> wordGoods = wordGoodsMapper.selectList(lqw);
//得到数据库中已有的所有分词
List<String> words = wordGoods.stream().map(x -> x.getWord()).toList();
//得到数据库中没有的分词
List<String> newWords = texts.stream().dropWhile(x -> words.contains(x)).toList();
//插入当前新数据
int success = goodsMapper.insert(goods);
if (success <= 0) {
return false;
}
Long id = goods.getId();
;
//修改数据库已有分词的数据
wordGoods.stream().forEach(x -> {
x.setGoodsId(x.getGoodsId() + "," + id);
wordGoodsMapper.updateById(x);
String goodsId = x.getGoodsId();
//保存到redis
for (String s : goodsId.split(",")) {
redisService.setBit(DealConstant.DEAL_SEARCH_KEY + x.getWord(), Long.valueOf(s), true);
}
});
//插入没有的分词
newWords.stream().forEach(word -> {
WordGoods x = new WordGoods();
x.setGoodsId(String.valueOf(id));
x.setWord(word);
wordGoodsMapper.insert(x);
//保存到redis
redisService.setBit(DealConstant.DEAL_SEARCH_KEY + x.getWord(), id, true);
});
} catch (IOException e) {
throw new RuntimeException(e);
}
return true;
}
@Override
public List<Goods> listByWord(String word) {
//分词操作
List<String> texts = null;
Set<Long> ids = new HashSet<>();
try {
texts = HanLPUtil.parse(word);
for (String x : texts) {
List<Long> bitsIndexes = redisService
.getBitIndexesByKey(DealConstant.DEAL_SEARCH_KEY + x);
ids.addAll(bitsIndexes);
}
//redis里面没有存储id
if (ids.isEmpty()) {
//取出数据库中包含该分词的所有行
LambdaQueryWrapper<WordGoods> lqw = new LambdaQueryWrapper<>();
lqw.in(WordGoods::getWord, texts.toArray());
List<WordGoods> wordGoods = wordGoodsMapper.selectList(lqw);
ids = getIds(wordGoods);
LambdaQueryWrapper<Goods> lqw1 = new LambdaQueryWrapper<>();
lqw1.in(!ids.isEmpty(), Goods::getId, ids);
List<Goods> goodsList = goodsMapper.selectList(lqw1);
return goodsList;
} else {
//redis里面有id了,直接查询
LambdaQueryWrapper<Goods> lqw1 = new LambdaQueryWrapper<>();
lqw1.in(!ids.isEmpty(), Goods::getId, ids);
List<Goods> goodsList = goodsMapper.selectList(lqw1);
return goodsList;
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
@NotNull
private Set<Long> getIds(List<WordGoods> wordGoods) {
Set<Long> ids = new HashSet<>();
for (WordGoods wordGood : wordGoods) {
String goodsId = wordGood.getGoodsId();
String[] split = goodsId.split(",");
for (int i = 0; i < split.length; i++) {
ids.add(Long.valueOf(split[i]));
}
}
return ids;
}
}
智能推荐
如何配置DNS服务的正反向解析_dns反向解析-程序员宅基地
文章浏览阅读3k次,点赞3次,收藏13次。root@server ~]# vim /etc/named.rfc1912.zones #添加如下内容,也可直接更改模板。[root@server ~]# vim /etc/named.conf #打开主配置文件,将如下两处地方修改为。注意:ip地址必须反向书写,这里文件名需要和反向解析数据文件名相同。新建或者拷贝一份进行修改。nslookup命令。_dns反向解析
设置PWM占空比中TIM_SetCompare1,TIM_SetCompare2,TIM_SetCompare3,TIM_SetCompare4分别对应引脚和ADC通道对应引脚-程序员宅基地
文章浏览阅读2.5w次,点赞16次,收藏103次。这个函数TIM_SetCompare1,这个函数有四个,分别是TIM_SetCompare1,TIM_SetCompare2,TIM_SetCompare3,TIM_SetCompare4。位于CH1那一行的GPIO口使用TIM_SetCompare1这个函数,位于CH2那一行的GPIO口使用TIM_SetCompare2这个函数。使用stm32f103的除了tim6和tim7没有PWM..._tim_setcompare1
多线程_进程和线程,并发与并行,线程优先级,守护线程,实现线程的四种方式,线程周期;线程同步,线程中的锁,Lock类,死锁,生产者和消费者案例-程序员宅基地
文章浏览阅读950次,点赞33次,收藏19次。多线程_进程和线程,并发与并行,线程优先级,守护线程,实现线程的四种方式,线程周期;线程同步,线程中的锁,Lock类,死锁,生产者和消费者案例
在 Linux 系统的用户目录下安装 ifort 和 MKL 库并配置_在linux系统的用户目录下安装ifort和mkl库并配置-程序员宅基地
文章浏览阅读2.9k次。ifort 编译器的安装ifort 编译器可以在 intel 官网上下载。打开https://software.intel.com/content/www/us/en/develop/tools/oneapi/components/fortran-compiler.html#gs.7iqrsm点击网页中下方处的 Download, 选择 Intel Fortran Compiler Classic and Intel Fortran Compiler(Beta) 下方对应的版本。我选择的是 l_在linux系统的用户目录下安装ifort和mkl库并配置
使用ftl文件生成图片中图片展示无样式,不显示_ftl格式pdf的样式调整-程序员宅基地
文章浏览阅读689次,点赞7次,收藏8次。些项目时需要一个生成图片的方法,我在网上找到比较方便且适合我去设置一些样式的生成方式之一就是使用Freemarker,在对应位置上先写好一个html格式的ftl文件,在对应位置用${参数名}填写上。还记得当时为了解决图片大小设置不上,搜索了好久资料,不记得是在哪看到的需要在里面使用width与height直接设置,而我当时用style去设置,怎么都不对。找不到,自己测试链接,准备将所有含有中文的图片链接复制一份,在服务器上存储一份不带中文的文件。突然发现就算无中文,有的链接也是打不开的。_ftl格式pdf的样式调整
orin Ubuntu 20.04 配置 Realsense-ROS_opt/ros/noetic/lib/nodelet/nodelet: symbol lookup -程序员宅基地
文章浏览阅读1.5k次,点赞6次,收藏12次。拉取librealsense。_opt/ros/noetic/lib/nodelet/nodelet: symbol lookup error: /home/admin07/reals
随便推点
操作系统精选习题——第四章_系统抖动现象的发生由什么引起的-程序员宅基地
文章浏览阅读3.4k次,点赞3次,收藏29次。一.单选题二.填空题三.判断题一.单选题静态链接是在( )进行的。A、编译某段程序时B、装入某段程序时C、紧凑时D、装入程序之前Pentium处理器(32位)最大可寻址的虚拟存储器地址空间为( )。A、由内存的容量而定B、4GC、2GD、1G分页系统中,主存分配的单位是( )。A、字节B、物理块C、作业D、段在段页式存储管理中,当执行一段程序时,至少访问()次内存。A、1B、2C、3D、4在分段管理中,( )。A、以段为单位分配,每._系统抖动现象的发生由什么引起的
UG NX 12零件工程图基础_ug-nx工程图-程序员宅基地
文章浏览阅读2.4k次。在实际的工作生产中,零件的加工制造一般都需要二维工程图来辅助设计。UG NX 的工程图主要是为了满足二维出图需要。在绘制工程图时,需要先确定所绘制图形要表达的内容,然后根据需要并按照视图的选择原则,绘制工程图的主视图、其他视图以及某些特殊视图,最后标注图形的尺寸、技术说明等信息,即可完成工程图的绘制。1.视图选择原则工程图合理的表达方案要综合运用各种表达方法,清晰完整地表达出零件的结构形状,并便于看图。确定工程图表达方案的一般步骤如下:口分析零件结构形状由于零件的结构形状以及加工位置或工作位置的不._ug-nx工程图
智能制造数字化工厂智慧供应链大数据解决方案(PPT)-程序员宅基地
文章浏览阅读920次,点赞29次,收藏18次。原文《智能制造数字化工厂智慧供应链大数据解决方案》PPT格式主要从智能制造数字化工厂智慧供应链大数据解决方案框架图、销量预测+S&OP大数据解决方案、计划统筹大数据解决方案、订单履约大数据解决方案、库存周转大数据解决方案、采购及供应商管理大数据模块、智慧工厂大数据解决方案、设备管理大数据解决方案、质量管理大数据解决方案、仓储物流与网络优化大数据解决方案、供应链决策分析大数据解决方案进行建设。适用于售前项目汇报、项目规划、领导汇报。
网络编程socket accept函数的理解_当在函数 'main' 中调用 'open_socket_accept'时.line: 8. con-程序员宅基地
文章浏览阅读2w次,点赞38次,收藏102次。在服务器端,socket()返回的套接字用于监听(listen)和接受(accept)客户端的连接请求。这个套接字不能用于与客户端之间发送和接收数据。 accept()接受一个客户端的连接请求,并返回一个新的套接字。所谓“新的”就是说这个套接字与socket()返回的用于监听和接受客户端的连接请求的套接字不是同一个套接字。与本次接受的客户端的通信是通过在这个新的套接字上发送和接收数_当在函数 'main' 中调用 'open_socket_accept'时.line: 8. connection request fa
C#对象销毁_c# 销毁对象及其所有引用-程序员宅基地
文章浏览阅读4.3k次。对象销毁对象销毁的标准语法Close和Stop何时销毁对象销毁对象时清除字段对象销毁的标准语法Framework在销毁对象的逻辑方面遵循一套规则,这些规则并不限用于.NET Framework或C#语言;这些规则的目的是定义一套便于使用的协议。这些协议如下:一旦销毁,对象不可恢复。对象不能被再次激活,调用对象的方法或者属性抛出ObjectDisposedException异常重复地调用对象的Disposal方法会导致错误如果一个可销毁对象x 包含或包装或处理另外一个可销毁对象y,那么x的Disp_c# 销毁对象及其所有引用
笔记-中项/高项学习期间的错题笔记1_大型设备可靠性测试可否拆解为几个部分进行测试-程序员宅基地
文章浏览阅读1.1w次。这是记录,在中项、高项过程中的错题笔记;https://www.zenwu.site/post/2b6d.html1. 信息系统的规划工具在制订计划时,可以利用PERT图和甘特图;访谈时,可以应用各种调查表和调查提纲;在确定各部门、各层管理人员的需求,梳理流程时,可以采用会谈和正式会议的方法。为把企业组织结构与企业过程联系起来,说明每个过程与组织的联系,指出过程决策人,可以采用建立过程/组织(Process/Organization,P/O)矩阵的方法。例如,一个简单的P/O矩阵示例,其中._大型设备可靠性测试可否拆解为几个部分进行测试