Python爬虫:设置Cookie解决网站拦截并爬取蚂蚁短租-程序员宅基地
技术标签: 2024年程序员学习 爬虫 python 开发语言
但很遗憾,报错了,说明蚂蚁金服防范措施还是挺到位的。

添加消息头的代码如下所示,这里先给出代码和结果,再教大家如何获取Cookie。
-- coding: utf-8 --
import urllib2
import re
from bs4 import BeautifulSoup
#爬虫函数
def gydzf(url):
user_agent=“Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36”
headers={“User-Agent”:user_agent}
request=urllib2.Request(url,headers=headers)
response=urllib2.urlopen(request)
contents = response.read()
soup = BeautifulSoup(contents, “html.parser”)
for tag in soup.find_all(‘dd’):
#短租房名称
for name in tag.find_all(attrs={“class”:“room-detail clearfloat”}):
fname = name.find(‘p’).get_text()
print u’[短租房名称]‘, fname.replace(’\n’,‘’).strip()
#短租房价格
for price in tag.find_all(attrs={“class”:“moy-b”}):
string = price.find(‘p’).get_text()
fprice = re.sub(“[¥]+”.decode(“utf8”), “”.decode(“utf8”),string)
fprice = fprice[0:5]
print u’[短租房价格]‘, fprice.replace(’\n’,‘’).strip()
#评分及评论人数
for score in name.find(‘ul’):
fscore = name.find(‘ul’).get_text()
print u’[短租房评分/评论/居住人数]‘, fscore.replace(’\n’,‘’).strip()
#网页链接url
url_dzf = tag.find(attrs={“target”:“_blank”})
urls = url_dzf.attrs[‘href’]
print u’[网页链接]‘, urls.replace(’\n’,‘’).strip()
urlss = ‘http://www.mayi.com’ + urls + ‘’
print urlss
#主函数
if name == ‘main’:
i = 1
while i<10:
print u’页码’, i
url = ‘http://www.mayi.com/guiyang/’ + str(i) + ‘/?map=no’
gydzf(url)
i = i+1
else:
print u"结束"
输出结果如下图所示:
页码 1
[短租房名称] 大唐东原财富广场–城市简约复式民宿
[短租房价格] 298
[短租房评分/评论/居住人数] 5.0分·5条评论·二居·可住3人
[网页链接] /room/851634765
http://www.mayi.com/room/851634765
[短租房名称] 大唐东原财富广场–清新柠檬复式民宿
[短租房价格] 568
[短租房评分/评论/居住人数] 2条评论·三居·可住6人
[网页链接] /room/851634467
http://www.mayi.com/room/851634467
…
页码 9
[短租房名称] 【高铁北站公园旁】美式风情+超大舒适安逸
[短租房价格] 366
[短租房评分/评论/居住人数] 3条评论·二居·可住5人
[网页链接] /room/851018852
http://www.mayi.com/room/851018852
[短租房名称] 大营坡(中大国际购物中心附近)北欧小清新三室
[短租房价格] 298
[短租房评分/评论/居住人数] 三居·可住6人
[网页链接] /room/851647045
http://www.mayi.com/room/851647045

接下来我们想获取详细信息
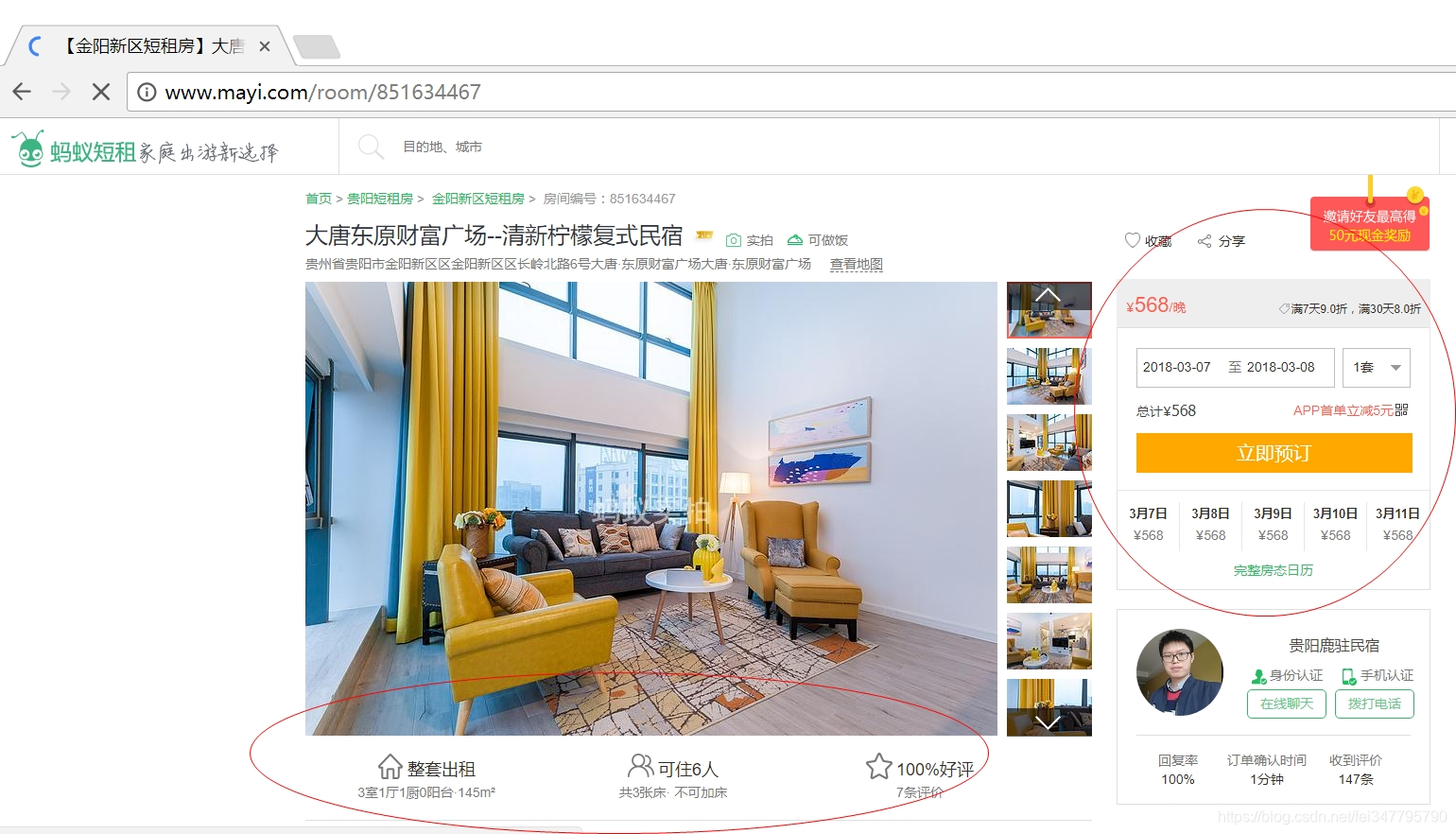
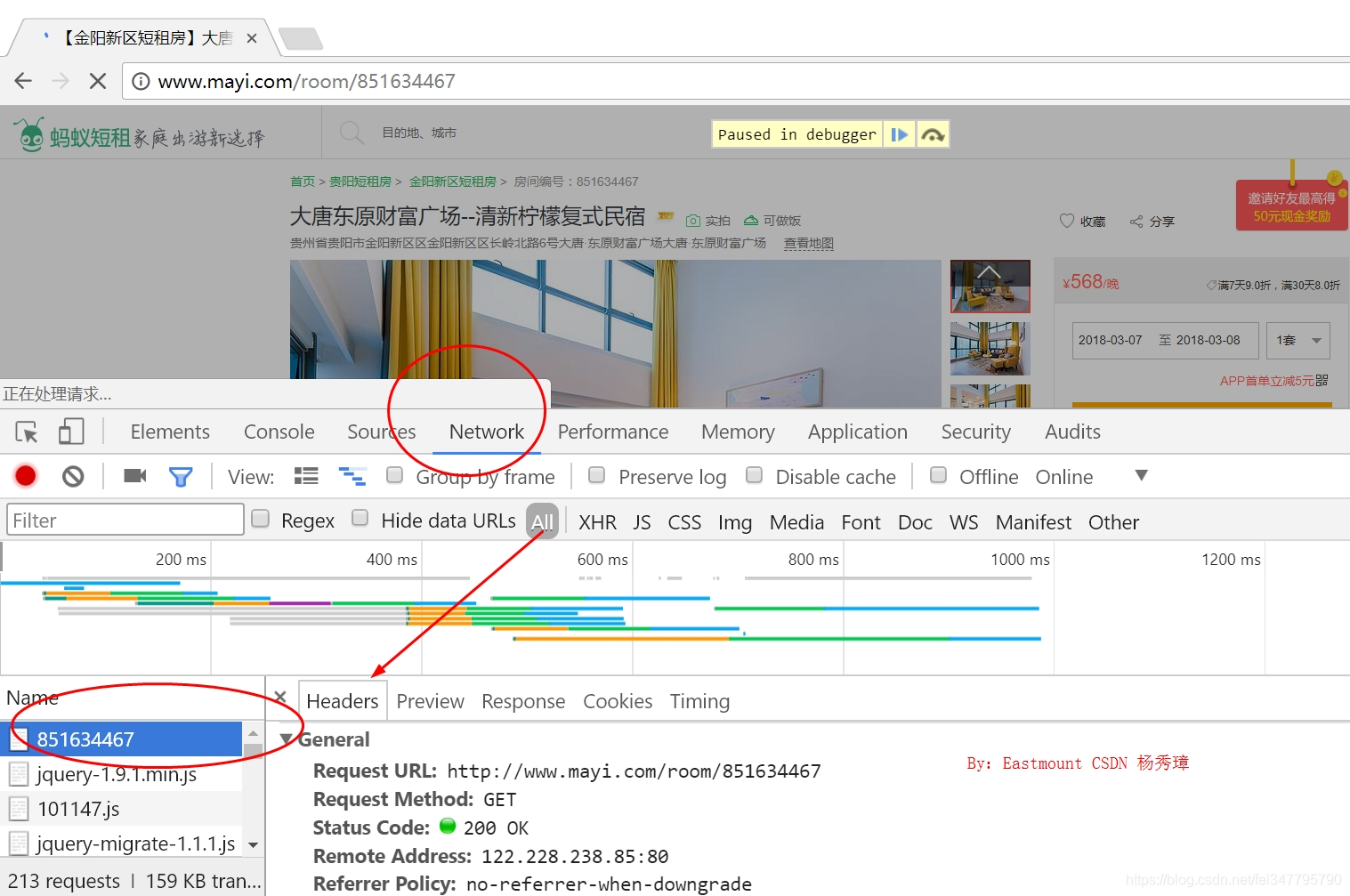
这里作者主要是提供分析Cookie的方法,使用浏览器打开网页,右键“检查”,然后再刷新网页。在“NetWork”中找到网页并点击,在弹出来的Headers中就隐藏这这些信息。
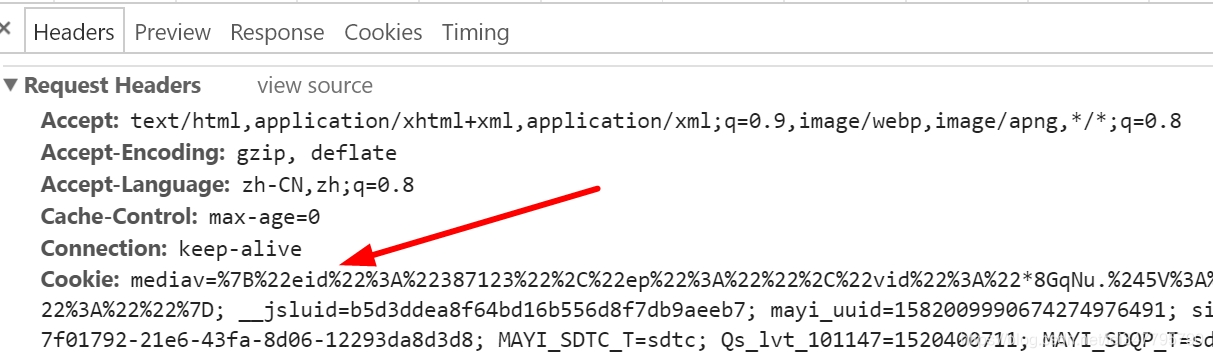
最常见的两个参数是Cookie和User-Agent,如下图所示:
然后在Python代码中设置这些参数,再调用Urllib2.Request()提交请求即可,核心代码如下:
user_agent=“Mozilla/5.0 (Windows NT 10.0; Win64; x64) … Chrome/61.0.3163.100 Safari/537.36”
cookie=“mediav=%7B%22eid%22%3A%22387123…b3574ef2-21b9-11e8-b39c-1bc4029c43b8”
headers={“User-Agent”:user_agent,“Cookie”:cookie}
request=urllib2.Request(url,headers=headers)
response=urllib2.urlopen(request)
contents = response.read()
soup = BeautifulSoup(contents, “html.parser”)
for tag1 in soup.find_all(attrs={“class”:“main”}):
注意,每小时Cookie会更新一次,我们需要手动修改Cookie值即可,就是上面代码的cookie变量和user_agent变量。完整代码如下所示:
import urllib2
import re
from bs4 import BeautifulSoup
import codecs
import csv
c = open(“ycf.csv”,“wb”) #write 写
c.write(codecs.BOM_UTF8)
writer = csv.writer
writer.writerow([“短租房名称”,“地址”,“价格”,“评分”,“可住人数”,“人均价格”])
#爬取详细信息
def getInfo(url,fname,fprice,fscore,users):
#通过浏览器开发者模式查看访问使用的user_agent及cookie设置访问头(headers)避免反爬虫,且每隔一段时间运行要根据开发者中的cookie更改代码中的cookie
user_agent=“Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36”
cookie=“mediav=%7B%22eid%22%3A%22387123%22eb7; mayi_uuid=1582009990674274976491; sid=42200298656434922.85.130.130”
headers={“User-Agent”:user_agent,“Cookie”:cookie}
request=urllib2.Request(url,headers=headers)
response=urllib2.urlopen(request)
contents = response.read()
soup = BeautifulSoup(contents, “html.parser”)
#短租房地址
for tag1 in soup.find_all(attrs={“class”:“main”}):
print u’短租房地址:’
for tag2 in tag1.find_all(attrs={“class”:“desWord”}):
address = tag2.find(‘p’).get_text()
print address
#可住人数
print u’可住人数:’
for tag4 in tag1.find_all(attrs={“class”:“w258”}):
yy = tag4.find(‘span’).get_text()
print yy
fname = fname.encode(“utf-8”)
address = address.encode(“utf-8”)
fprice = fprice.encode(“utf-8”)
fscore = fscore.encode(“utf-8”)
fpeople = yy[2:3].encode(“utf-8”)
ones = int(float(fprice))/int(float(fpeople))
#存储至本地
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Python工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Python开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Python开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip1024c (备注Python)

如果你也是看准了Python,想自学Python,在这里为大家准备了丰厚的免费学习大礼包,带大家一起学习,给大家剖析Python兼职、就业行情前景的这些事儿。
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
二、学习软件
工欲善其必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。

四、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。


四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
五、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。
成为一个Python程序员专家或许需要花费数年时间,但是打下坚实的基础只要几周就可以,如果你按照我提供的学习路线以及资料有意识地去实践,你就有很大可能成功!
最后祝你好运!!!
战案例来学习。
五、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。
成为一个Python程序员专家或许需要花费数年时间,但是打下坚实的基础只要几周就可以,如果你按照我提供的学习路线以及资料有意识地去实践,你就有很大可能成功!
最后祝你好运!!!
智能推荐
5个超厉害的资源搜索网站,每一款都可以让你的资源满满!_最全资源搜索引擎-程序员宅基地
文章浏览阅读1.6w次,点赞8次,收藏41次。生活中我们无时不刻不都要在网站搜索资源,但就是缺少一个趁手的资源搜索网站,如果有一个比较好的资源搜索网站可以帮助我们节省一大半时间!今天小编在这里为大家分享5款超厉害的资源搜索网站,每一款都可以让你的资源丰富精彩!网盘传奇一款最有效的网盘资源搜索网站你还在为找网站里面的资源而烦恼找不到什么合适的工具而烦恼吗?这款网站传奇网站汇聚了4853w个资源,并且它每一天都会持续更新资源;..._最全资源搜索引擎
Book类的设计(Java)_6-1 book类的设计java-程序员宅基地
文章浏览阅读4.5k次,点赞5次,收藏18次。阅读测试程序,设计一个Book类。函数接口定义:class Book{}该类有 四个私有属性 分别是 书籍名称、 价格、 作者、 出版年份,以及相应的set 与get方法;该类有一个含有四个参数的构造方法,这四个参数依次是 书籍名称、 价格、 作者、 出版年份 。裁判测试程序样例:import java.util.*;public class Main { public static void main(String[] args) { List <Book>_6-1 book类的设计java
基于微信小程序的校园导航小程序设计与实现_校园导航微信小程序系统的设计与实现-程序员宅基地
文章浏览阅读613次,点赞28次,收藏27次。相比于以前的传统手工管理方式,智能化的管理方式可以大幅降低学校的运营人员成本,实现了校园导航的标准化、制度化、程序化的管理,有效地防止了校园导航的随意管理,提高了信息的处理速度和精确度,能够及时、准确地查询和修正建筑速看等信息。课题主要采用微信小程序、SpringBoot架构技术,前端以小程序页面呈现给学生,结合后台java语言使页面更加完善,后台使用MySQL数据库进行数据存储。微信小程序主要包括学生信息、校园简介、建筑速看、系统信息等功能,从而实现智能化的管理方式,提高工作效率。
有状态和无状态登录
传统上用户登陆状态会以 Session 的形式保存在服务器上,而 Session ID 则保存在前端的 Cookie 中;而使用 JWT 以后,用户的认证信息将会以 Token 的形式保存在前端,服务器不需要保存任何的用户状态,这也就是为什么 JWT 被称为无状态登陆的原因,无状态登陆最大的优势就是完美支持分布式部署,可以使用一个 Token 发送给不同的服务器,而所有的服务器都会返回同样的结果。有状态和无状态最大的区别就是服务端会不会保存客户端的信息。
九大角度全方位对比Android、iOS开发_ios 开发角度-程序员宅基地
文章浏览阅读784次。发表于10小时前| 2674次阅读| 来源TechCrunch| 19 条评论| 作者Jon EvansiOSAndroid应用开发产品编程语言JavaObjective-C摘要:即便Android市场份额已经超过80%,对于开发者来说,使用哪一个平台做开发仍然很难选择。本文从开发环境、配置、UX设计、语言、API、网络、分享、碎片化、发布等九个方面把Android和iOS_ios 开发角度
搜索引擎的发展历史
搜索引擎的发展历史可以追溯到20世纪90年代初,随着互联网的快速发展和信息量的急剧增加,人们开始感受到了获取和管理信息的挑战。这些阶段展示了搜索引擎在技术和商业模式上的不断演进,以满足用户对信息获取的不断增长的需求。
随便推点
控制对象的特性_控制对象特性-程序员宅基地
文章浏览阅读990次。对象特性是指控制对象的输出参数和输入参数之间的相互作用规律。放大系数K描述控制对象特性的静态特性参数。它的意义是:输出量的变化量和输入量的变化量之比。时间常数T当输入量发生变化后,所引起输出量变化的快慢。(动态参数) ..._控制对象特性
FRP搭建内网穿透(亲测有效)_locyanfrp-程序员宅基地
文章浏览阅读5.7w次,点赞50次,收藏276次。FRP搭建内网穿透1.概述:frp可以通过有公网IP的的服务器将内网的主机暴露给互联网,从而实现通过外网能直接访问到内网主机;frp有服务端和客户端,服务端需要装在有公网ip的服务器上,客户端装在内网主机上。2.简单的图解:3.准备工作:1.一个域名(www.test.xyz)2.一台有公网IP的服务器(阿里云、腾讯云等都行)3.一台内网主机4.下载frp,选择适合的版本下载解压如下:我这里服务器端和客户端都放在了/usr/local/frp/目录下4.执行命令# 服务器端给执_locyanfrp
UVA 12534 - Binary Matrix 2 (网络流‘最小费用最大流’ZKW)_uva12534-程序员宅基地
文章浏览阅读687次。题目:http://acm.hust.edu.cn/vjudge/contest/view.action?cid=93745#problem/A题意:给出r*c的01矩阵,可以翻转格子使得0表成1,1变成0,求出最小的步数使得每一行中1的个数相等,每一列中1的个数相等。思路:网络流。容量可以保证每一行和每一列的1的个数相等,费用可以算出最小步数。行向列建边,如果该格子是_uva12534
免费SSL证书_csdn alphassl免费申请-程序员宅基地
文章浏览阅读504次。1、Let's Encrypt 90天,支持泛域名2、Buypass:https://www.buypass.com/ssl/resources/go-ssl-technical-specification6个月,单域名3、AlwaysOnSLL:https://alwaysonssl.com/ 1年,单域名 可参考蜗牛(wn789)4、TrustAsia5、Alpha..._csdn alphassl免费申请
测试算法的性能(以选择排序为例)_算法性能测试-程序员宅基地
文章浏览阅读1.6k次。测试算法的性能 很多时候我们需要对算法的性能进行测试,最简单的方式是看算法在特定的数据集上的执行时间,简单的测试算法性能的函数实现见testSort()。【思想】:用clock_t计算某排序算法所需的时间,(endTime - startTime)/ CLOCKS_PER_SEC来表示执行了多少秒。【关于宏CLOCKS_PER_SEC】:以下摘自百度百科,“CLOCKS_PE_算法性能测试
Lane Detection_lanedetectionlite-程序员宅基地
文章浏览阅读1.2k次。fromhttps://towardsdatascience.com/finding-lane-lines-simple-pipeline-for-lane-detection-d02b62e7572bIdentifying lanes of the road is very common task that human driver performs. This is important ..._lanedetectionlite